
結構化資料(Structured Data)就是用一段標準化的程式碼,明確告訴 Google 你這頁是文章、是產品、還是 FAQ,讓搜尋引擎不用再從文字去「猜」。根據 Google Search Central 的官方說明,結構化資料能讓你的頁面具備取得複合式搜尋結果(rich results)的資格,並幫助搜尋引擎正確理解內容類型。它不是排名的保證,卻是你能不能拿到特殊版面、甚至被 AI 搜尋引用的關鍵入場券。
TL;DR:結構化資料是幫機器翻譯你內容的規格標籤,不是排名開關。做對它能拿到複合式搜尋結果、提升點閱率,並提高被 AI 搜尋引用的機會;根據 Google 官方搜尋結果庫,目前支援超過 30 種以上的結構化資料類型。
文章目錄
結構化資料是什麼?用一段話講清楚
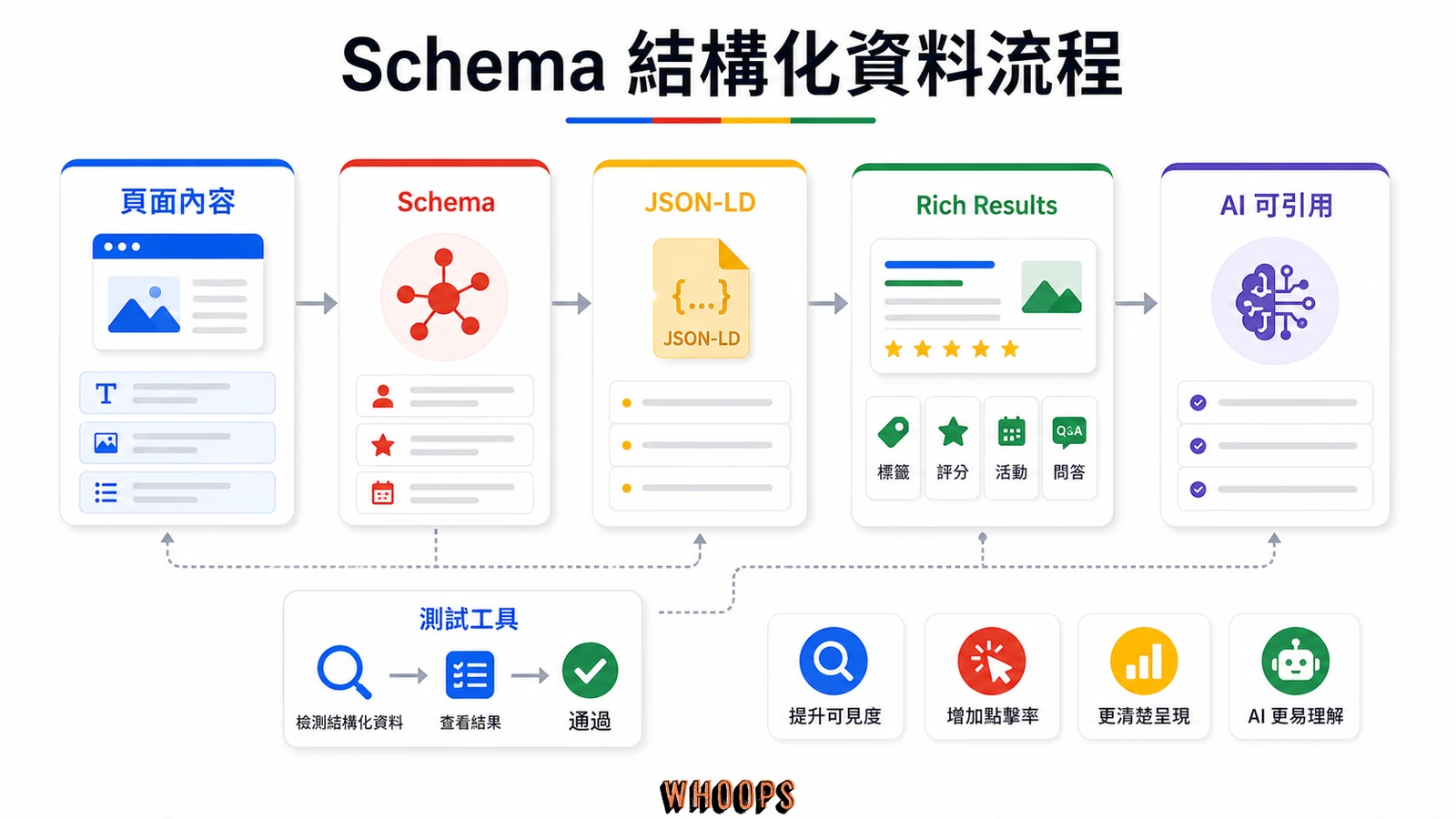
結構化資料是一組按照固定格式寫成的程式碼,加在網頁裡,讓搜尋引擎能「讀懂」這頁的內容類型與欄位,而不必從文字去推測。它的本質就是幫機器翻譯你的內容。用白話說,普通的 HTML 像寫給人看的文章,結構化資料則像夾在文章裡的一張「規格標籤」,Google 看標籤就知道這頁是食譜、有價格、有評價,還是某個活動的時間地點。這跟你在 SEO 上做的一切是同一件事的延伸:讓搜尋引擎更有效率地理解你。
換個比喻也許更好懂。想像你寄一個包裹給 Google,HTML 內容是箱子裡的東西,結構化資料就是貼在箱子外面的貨運標籤:寫清楚裡面是什麼、多重、誰寄的、什麼時候寄出。沒有標籤,物流中心還是得打開箱子一件件翻,既慢又容易翻錯;有了標籤,它一眼就知道怎麼分類、要送到哪個貨架。搜尋引擎處理幾十億個網頁,省下來的「翻箱時間」就是你被正確分類的機會。
一個頁面可以、而且常常應該放多組結構化資料。例如一篇部落格文章同時標 Article、BreadcrumbList(麵包屑)和 FAQPage(常見問答)三組是相當常見的組合,分別照顧「這是什麼內容」「它在你網站裡的位置」「它回答了哪些問題」三個層次。這也是為什麼很多人在做 站內 SEO 時,會把結構化資料列為基礎建設之一,而不是進階選項。你可以把它想成是 頁面 SEO 之外,另一條「幫機器導航」的路:頁面 SEO 管給人看的內容,結構化資料管單一頁面是什麼。
要把它跟作弊手法分清楚。結構化資料是 Google 公開認可、甚至主動鼓勵的標記方式,跟過去那種塞 meta keywords、藏隱藏文字的黑帽手法完全是兩回事。它不會把你送進懲罰名單,前提是你標的內容跟頁面上看得到的東西一致。說到底,結構化資料不是「加了就會排名」的開關,而是「讓你具備被特殊呈現資格」的門票。少了它,很多進階曝光形式你連報名的機會都沒有。
我自己第一次接觸時也以為它很玄,後來才發現它其實就是在 搜尋結果頁 上幫你「搶版面」的工具。你寫得再好,如果 Google 讀不懂「這是一篇 2026 年的教學文章」「作者是誰」,它就沒辦法用複合式搜尋結果的形式把你秀出來。結構化資料就是把這些已經存在的事實,再用機器讀得懂的方式說一次。
Schema.org 與 JSON-LD:三個你一定會搞混的名詞一次分清楚
Schema.org 是「詞彙字典」,Schema markup 是「動作」,JSON-LD 則是「寫法格式」,Google 最推薦的一種。三者是字典、動作、格式的關係,不是同一層東西。很多人把這三個名詞混在一起講,結果越看越糊塗。我剛學的時候也以為它們是三件不同的事,繞了一大圈才搞懂其實是一條鏈:先有字典,再用字典裡的詞來標記,標記時挑一種格式來寫。
Schema.org 是誰維護的字典
Schema.org 由 Google、Microsoft、Yahoo、Yandex 在 2011 年共同發起並持續維護(來源:schema.org 官方),目的是給所有搜尋引擎一套共通的詞彙,讓網站不必為每個引擎寫不同標記。它定義了 Article、Product、Event、LocalBusiness 等數百種類型,以及每種類型可用哪些欄位(例如 author、datePublished、price)。你在做 關鍵字最佳化 時挑詞,在做結構化資料時挑的就是這些類型與欄位。
三種格式差在哪:JSON-LD、Microdata、RDFa
同樣一份標記可以用三種格式寫,差別在於「寫在哪、好不好維護」:
| 格式 | 寫在哪 | Google 推薦程度 | 維護難度 |
|---|---|---|---|
| JSON-LD | 獨立一段 <script> 區塊 | 官方首選 | 低,與內容分離 |
| Microdata | 嵌在 HTML 標籤屬性裡 | 仍支援但非首選 | 中,與內容綁在一起 |
| RDFa | 嵌在 HTML 標籤屬性裡 | 少見 | 高,學習曲線陡 |
Google 在 Search Central 明確指定 JSON-LD 為首選,原因很實際:它跟網頁內容分離、好維護、CMS 與外掛支援度高,而且不會把你原本的 HTML 弄得亂七八糟。這對用 WordPress 架站的人尤其友善,因為 WordPress SEO 外掛多半可以直接輸出 JSON-LD,不用你手動改佈景主題。
實務上我會建議:除非你有legacy 系統非得用 Microdata 不可,否則一律選 JSON-LD。它就是一段包在 <script type="application/ld+json"> 裡的資料,加在 <head> 或頁尾都行,改的時候也不會動到文章正文。這也是為什麼連 技術 SEO 的入門檢查表,都會把「全站改用 JSON-LD」列為基本款。
結構化資料對 SEO 到底有沒有用?不藏私講三個實際影響
結構化資料本身不是直接的排名因素,但它透過三條路間接拉抬你的能見度:取得複合式搜尋結果(提升 點閱率)、幫助搜尋引擎正確分類內容、以及提高被 AI 搜尋引用的機會。把它想成「放大器」而不是「引擎」。Google 多年來也重申,結構化資料不是排名保證,但它確實能改變你在結果頁上的呈現方式。
影響一:複合式搜尋結果讓你的版面變大
第一個、也是最直接的好處,是拿到複合式搜尋結果。星級評分、FAQ 可展開清單、麵包屑、活動時間、價格區間,這些都會讓你的版面比別人多佔一兩行,視覺上更顯眼。版面變大、資訊變完整,點閱率自然有機會提升。這也是為什麼很多在做 如何改善 SEO 的人,會把結構化資料列為「不改內容也能提升點擊」的少數手段之一。
影響二:強化語意理解與 E-E-A-T 訊號
第二個影響比較隱性,但對長期排名更重要。結構化資料幫搜尋引擎理解「這頁講的是哪個實體、作者是誰、屬於哪個組織」,這直接強化了 E-E-A-T(經驗、專業、權威、信任)訊號。當你能用 author 欄位明確標示作者、用 publisher 標示發布組織,Google 就更容易把你這頁歸進某個主題權威體系裡。這對 YMYL(Your Money Your Life)類型的內容尤其關鍵。
影響三:為 AI 搜尋提供可引用的事實
第三個影響是 2026 年才浮上檯面的:AI 搜尋引用。Google AI Overviews、ChatGPT、Perplexity 這類生成式搜尋需要的是「機器可讀、可驗證的事實單位」,而結構化資料正好提供這類結構化事實。不過這裡我要誠實說:目前沒有公開資料能證明「加了某個 schema 就一定被 AI 引用」,但把事實標清楚,至少讓 AI 有東西可抓。這跟 GEO(生成式引擎最佳化)和 AEO(答案引擎最佳化)的邏輯一致。
沒有任何工具能保證排名,結構化資料是地基不是保證書。但地基鬆了,上面蓋什麼都會歪。從 SEO 排名因素 的全貌來看,結構化資料佔的權重不大,卻是少數「做了幾乎不會壞事、不做會少掉很多機會」的項目。
這裡要小心一個常見的誤會。有人會問:既然它不是排名因素,那不做會怎樣?現實是,當你的對手有結構化資料、你沒有,在搜尋結果頁上,他的版面就會比你大、資訊比你完整,點閱率差距會慢慢累積成流量差距。SEO 很少是單一動作的勝負,而是一堆「多做一點」的複利。結構化資料就是那種成本低、複利效果穩定的投資,跟 網站結構與外部連結最佳化 屬於同一類基礎工程。當你的內容、架構、反向連結 都到位之後,結構化資料就是那個把所有努力「翻譯給機器聽」的最後一哩路,不做就等於讓前面那些努力打折。
2026 年最值得做的 5 種 Schema 類型(從報酬率最高開始)
依報酬率排序:Article(或 BlogPosting)、BreadcrumbList、FAQPage、Organization/LocalBusiness、Product/Review。前兩個幾乎所有內容站都該裝,後三個依你的網站類型挑選。先做齊這五個,再談進階。如果你只能挑一個,我會說先把 Article 做對,因為它跟作者、發布時間、E-E-A-T 全部連動。
| Schema 類型 | 適合誰 | 能拿到的 rich result | 實作難度 |
|---|---|---|---|
| Article / BlogPosting | 部落格、媒體 | 作者、發布時間、圖片 | 低 |
| BreadcrumbList | 所有網站 | 麵包屑導航 | 低 |
| FAQPage | 問答型內容 | 可展開問答清單(視情況) | 中 |
| Organization / LocalBusiness | 品牌、在地商家 | 知識圖譜、商家資訊 | 中 |
| Product / Review | 電商、評論站 | 價格、庫存、星級 | 中高 |
Article:內容站的必備款
Article 或 BlogPosting 標的是 author、datePublished、dateModified、publisher、image。2026 年的重點是 author 跟 E-E-A-T 連動越來越深,Google 越來越在意「這篇文章是誰寫的、他夠不夠格」。這也是為什麼做 SEO 文章寫作 時,作者資訊要寫清楚、最好還能連到作者頁或 sameAs 指向社群。一篇有 author 標記的文章,在 自然排名 的信任累積上會比匿名文章快。
BreadcrumbList:全站通用、幾乎零成本
BreadcrumbList 標的是使用者在網站裡的位置路徑,例如「首頁 > SEO 教學 > 結構化資料」。它幾乎零成本,WordPress 用 Rank Math、Yoast 這類外掛多半自動生成。它同時幫使用者和搜尋引擎理解你的 網站架構,跟 內部連結最佳化 是相輔相成的兩件事。如果連這個都沒做,等於是免費的版面白白放掉。
FAQPage:期待值要設對
FAQPage 適合問答型內容,但這裡要講清楚現況,避免給錯期待。Google 從 2023 年起大幅收窄 FAQ rich result 的顯示範圍,現在多半只剩特定類型的權威網站才會觸發,一般中小網站即使標了 FAQPage,也不一定能在搜尋結果展開。不過標了仍然有好處:它幫 AI 搜尋更容易抓到你的問答,跟 AI Overviews 與 AISO 的引用邏輯接得上。把它當成「為 AI 標記」,心態會比較健康。
Organization 與 LocalBusiness:品牌與在地商家
Organization 標的是你的組織資訊(名稱、logo、社群連結),LocalBusiness 則多了地址、營業時間、電話。這兩者在 2026 年跟 Google 商家檔案、知識圖譜(knowledge panel)的連動越來越深,做 在地搜尋 或 在地 SEO 的商家幾乎必做。用 sameAs 把官方社群、維基百科連起來,能強化實體的跨網路一致性。
Product 與 Review:電商與評論站
Product 標價格、庫存、圖片,Review 標評論與星級,兩者常搭配使用。這對電商轉換的影響很直接,搜尋結果上多了價格與星級,點擊意願會明顯不同。如果你經營的是產品頁,這篇 產品結構化資料指南 有更細的操作步驟。對做 轉換率 的人來說,這是少數能同時顧 SEO 與轉換的標記。
選 Schema 類型時有一個判斷原則:看你的頁面對使用者「最重要的那個身份」是什麼。一個頁面可能是文章,同時也是產品評論,但你得挑最主要的那個來標,不要全部都塞進同一組、互相打架。舉例來說,一篇開箱文可以同時標 Article(因為它是文章)和 Review(因為它有評論),但如果你標成 Product,就得確認頁面上真的有價格、庫存這些欄位,否則 Google 會判定不符。這跟 搜尋意圖 的判斷邏輯相通:先想清楚使用者來這頁是為了什麼,再決定怎麼標。挑錯類型,比不標還浪費時間。
不會寫程式也能上手:JSON-LD 實作三步驟(含可直接複製的範本)
三步驟:用現成範本填空、換成你自己的真實資訊、用 Google 官方工具測試通過再上線。全程不用從零寫程式,範本套上去改欄位就行。這是我最常被問的問題,所以把流程拆到最細。很多讀者卡住的不是技術,而是「不知道可以從哪裡複製起」,下面三段範本就是你的起點,照著貼進網站的頁尾或 header 程式碼區塊即可。
步驟一:選範本照樣填空
下面三段是 Article、BreadcrumbList、FAQPage 的 JSON-LD 範本,可以直接複製、改欄位。重點是結構不能亂動,只換引號裡的值。
Article 範本:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "你的文章標題",
"author": { "@type": "Person", "name": "作者名" },
"datePublished": "2026-06-17",
"dateModified": "2026-06-17",
"image": "https://你的網站/featured.jpg",
"publisher": {
"@type": "Organization",
"name": "你的組織名稱",
"logo": { "@type": "ImageObject", "url": "https://你的網站/logo.png" }
}
}
</script>
BreadcrumbList 範本:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{ "@type": "ListItem", "position": 1, "name": "首頁", "item": "https://你的網站/" },
{ "@type": "ListItem", "position": 2, "name": "分類名", "item": "https://你的網站/分類/" },
{ "@type": "ListItem", "position": 3, "name": "目前頁面標題", "item": "https://你的網站/這篇文章/" }
]
}
</script>
FAQPage 範本:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "第一個問題?",
"acceptedAnswer": { "@type": "Answer", "text": "第一個答案。" }
},
{
"@type": "Question",
"name": "第二個問題?",
"acceptedAnswer": { "@type": "Answer", "text": "第二個答案。" }
}
]
}
</script>
步驟二:把欄位換成你自己的真實資料
把上面範本裡的假資料換成真實的標題、作者、發布日期、組織名稱、logo 網址。這裡有一條 Google 明文規定不能違反:JSON-LD 裡的資料必須跟頁面上看得到的內容一致。你標了 author 是「王小明」,頁面上就得真的看得到王小明這個名字;標了 FAQ 問答,頁面上就得有對應的可見問答。不一致就是踩紅線,輕則 rich result 不顯示,重則被當成操縱。這跟 實用內容準則 的精神一致:給機器看的,不能比給人看的還多。
日期欄位有個小地方容易踩雷。datePublished 是第一次發布的日期,dateModified 是最近一次更新的日期,兩者要用 ISO 格式(例如 2026-06-17)。很多人會把 dateModified 直接抄成 datePublished,結果更新了內容,機器卻以為這是一篇沒動過的舊文。如果你是常更新內容的網站,這兩個欄位分清楚,才能讓搜尋引擎與 AI 知道你的內容是「活的」,而不是放著長灰塵的存檔。這也跟 字數與更新 的討論有關:持續維護的舊文,往往比一篇全新但没人理會的長文更有價值。
步驟三:測試、測試、再測試
上線前用兩個官方工具雙重驗證:Google Rich Results Test(看 Google 認不認得、會不會觸發 rich result)與 Schema Markup Validator(看 schema.org 詞彙用得對不對)。兩個都過再上線。這一步千萬別省,因為 JSON-LD 少一個逗號、多一個引號就可能整段失效,而這種錯誤用肉眼幾乎抓不出來。實務上我會建議把測試當成「上線前的健康檢查」,就像發文前先預覽一次,這個習慣能幫你擋掉九成的事故。
WordPress 使用者可以更省事:Rank Math、Yoast 這類外掛能自動生成大部分 Schema,搭配 Site Kit by Google 還能在後台直接看資料。但手動檢查輸出結果仍然是必要的,因為外掛預設值不見得符合你的內容。我曾看過一個客戶外掛預設開了全站 FAQ schema,結果每篇都用同一組假問答,後來被 Google 直接停掉 rich result,回頭清了兩個禮拜才救回來。這也呼應 技術 SEO 常見盲點:自動化的東西,更要手動驗證。
加了卻沒效果?結構化資料的 5 個常見錯誤與排除方法
最常見的五個原因:內容與標記不一致、用了 Google 不再支援的類型、JSON-LD 語法錯誤、結構化資料指向看不到的隱藏內容、以及最常被忽略的「其實已生效只是還在等待 Google 重新檢索」。逐一檢查就能定位問題。先別急著懷疑 Schema 壞了,九成時候是 Google 還沒回來看。
錯誤一:標記與頁面可見內容不符
這是最常見也最致命的錯誤。例如 FAQ 寫在 JSON-LD 裡、頁面上卻沒有對應的可見問答,或 Product 標了某個價格、頁面上顯示的卻是另一個。Google 明文禁止這種「只給機器看」的標記。排查方法是把 JSON-LD 裡的每一個欄位,逐一對照頁面上眼睛看得到的內容,對不上就改。這也跟 假 E-E-A-T 手法的風險 是同一類問題:造假會被算法抓到。
錯誤二:用了已淘汰或收窄的類型
有些 rich result 在 2026 年已經不容易觸發了,要誠實面對。HowTo rich result 已於 2023 年底對一般網站停用,FAQ rich result 也大幅收窄,現在多半只給權威型網站。你可以標,但不保證會顯示。想知道目前 Google 還支援哪些,直接查 Google 官方搜尋結果庫 最準,不要相信過時的教學。這也是 SEO 趨勢 變動最快的一塊。
錯誤三:JSON-LD 語法錯誤
逗號、引號、大括號、巢狀結構,少一個就整段失效。好消息是 Rich Results Test 會直接把錯誤行號指出來,照著改就行。常見的雷包括:最後一個屬性多了一個逗號、字串用了全形引號、巢狀物件少了一層大括號。這跟 網站程式碼最佳化 的除錯邏輯一樣,靠工具不靠肉眼。
錯誤四:隱藏內容標記
把問答用 display:none 藏起來、只出現在 JSON-LD 裡,會被視為操縱。Google 要的是「使用者真的看得到」的內容。如果你怕 FAQ 佔版面,正確做法是用可展開的 <details> 元件,而不是把它藏掉。這也跟 重複內容 的處理原則類似:給人和給機器的內容要一致。
錯誤五:耐心問題,其實還在等檢索
這是最容易被忽略的。Google 重新檢索與生效通常需要數天到數週,視你網站的檢索頻率而定。用 Google 搜尋 的檢索機制來說,新內容本來就要排隊。追蹤進度的正確工具是 Search Console 的「增強功能」報告,看它有沒有出現「已偵測」「有效」「錯誤」等狀態。如果在那裡顯示有效,就只是還沒輪到你在結果頁發光而已。
判斷到底有沒有生效,有一個簡單的順序。先在 Rich Results Test 跑你的網址,確認標記被正確解析、沒有錯誤;再到 Search Console 的「增強功能」報告看狀態是不是「有效」;最後才是到搜尋結果頁實際搜尋看版面。很多人第一步沒過就急著到搜尋結果找,找不到就以為失敗,其實是標記本身有問題。先把工具鏈走完,再下結論,這也是 審視 SEO 策略 該建立的排查習慣。
2026 年 AI 搜尋崛起後,結構化資料的角色變了什麼?
結構化資料在 AI 搜尋時代不但沒有退場,反而更重要,但價值從「拿 rich result 版面」轉向「讓 AI 模型更容易正確理解並引用你的內容」。調整重點放在事實型欄位、實體連結、與權威訊號三件事。我自己的觀察是,AI 搜尋偏愛答案清楚、結構整齊的頁面,而結構化資料就是把「整齊」這件事做到極致。
觀念轉換:從搶版面到餵事實
AI 搜尋需要的是「機器可讀、可驗證的事實單位」。一個明確標了發布日期、作者、來源組織的頁面,對 AI 來說就是一塊好消化的資料;相反地,一堆只有漂亮文筆、卻沒有任何機器可讀標記的內容,AI 要花更多力氣猜。這也是為什麼做 AI 搜尋 SEO 的人,會把結構化資料當成「給 AI 的摘要」。它跟你做 llms.txt 或 Google Web Guide 的精神是相通的:降低機器理解你的成本。
強化重點一:事實型欄位要精準
日期、數字、作者、來源組織,這些是 AI 引用時最常抓的欄位,也是最容易出錯的。一個標錯的日期,可能讓 AI 把你判定成過時內容而不引用。這跟你在 標題標籤 與 中繼描述 上追求精準,是同一件事的延伸:事實欄位不容含糊。
強化重點二:用 sameAs 建立實體一致性
sameAs 是 schema.org 裡一個常被忽略的欄位,它的作用是「告訴機器:這個實體在別的地方也是我」。把官方社群、維基百科、Google 商家檔案連起來,就能建立實體的跨網路一致性,強化 E-E-A-T。這對品牌型網站尤其重要,跟 網域權重 與 外部連結 累積權威是互補的兩條路。
具體怎麼做?在 Organization 或 Person 類型底下,加一個 sameAs 陣列,把你的 Facebook 粉專、YouTube 頻道、LinkedIn、官方網站、維基百科條目(如果有的話)全部列進去。如果你的品牌有在 Google 商家檔案登錄,也把它加進去。這樣一來,不管 AI 從哪個來源抓到「你是誰」,它都能透過 sameAs 把這些零散的訊號串成同一個實體。這跟 停留時間、自然流量 這類行為訊號不同,它是「身分層」的一致性,是機器判斷你是不是權威來源的依據之一。
強化重點三:沒有「專門給 AI 的 schema」
要破除一個迷思:Google 並沒有推出「AI Overviews 專屬標記」,也沒有「做了就一定被 AI 引用」的 schema。你能做的是沿用既有規範、把內容組織清楚,讓不管是傳統搜尋還是 AI 總覽、Google AI Mode 都讀得懂。目前 AI 引用行為仍在演進中,不過度承諾。把 查詢擴充 跟 零點擊搜尋 的趨勢一起看,你會更清楚為什麼「讓內容好被引用」比「搶排名」更值得長期投資。
結構化資料 FAQ:讀者最常問的 7 個問題
下面精選 7 個高搜尋量問句,每題先給結論再說原因。這段同時標了 FAQPage schema,方便 AI 搜尋抓取,你也可以把它當成快速決策參考:遇到問題時直接跳到對應的問答看答案。
Q1:結構化資料會直接影響排名嗎?
不會直接影響排名。Google 已多次說明結構化資料不是排名因素,但它透過複合式搜尋結果與語意理解,能間接提升能見度與點閱率。把它當成「放大既有內容價值」的工具,而不是「把爛內容推上去」的捷徑,心態會比較踏實。更多排名觀念可參考 Google 公開最重要的前 3 個 SEO 排名因素。
Q2:JSON-LD、Microdata、RDFa 要選哪個?
選 JSON-LD。Google 在 Search Central 公開指定它為首選,原因前面提過:與內容分離、好維護、外掛支援度高。除非你有舊系統限制,否則沒有理由挑另外兩種。
Q3:FAQ schema 現在還有用嗎?
對特定類型內容仍有效,但 Google 從 2023 年起收窄了 FAQ rich result 的顯示範圍,一般網站不一定能在結果頁展開。不過標了仍對 AI 搜尋有幫助,因為它讓問答更容易被機器抓取。期待值設對就好。
Q4:不會寫程式能用結構化資料嗎?
可以。WordPress 用 Rank Math、Yoast 等外掛就能自動生成大部分 Schema,或是直接套上面給的範本改欄位。重點是資料要正確、要跟頁面內容一致,這比會不會寫程式重要得多。想從零開始也可以看 SEO 新手入門教學。
Q5:加了之後多久會生效?
通常數天到數週,視 Google 檢索你網站的頻率而定。大型權威網站可能幾天就生效,新站或低頻被檢索的站可能要等更久。用 Search Console 的「增強功能」報告追蹤狀態最準。耐心是這件事的一部分,別急著認定它沒效。
Q6:結構化資料會不會被當成作弊?
只要標記與頁面可見內容一致就不會。Google 鼓勵的是「如實描述」,處罰的是「隱藏或造假」。把問答藏起來、標了頁面上沒有的價格、用假作者,這些才算作弊。搞不清楚紅線在哪,可以先讀 黑帽 SEO 與 灰帽 SEO 的差異。
Q7:AI 搜尋時代還需要做嗎?
需要。價值從「搶 rich result 版面」轉向「讓 AI 正確理解並引用」,是長期投資。結構化資料讓你的內容更容易被 AI 當成可驗證的事實來源,這在 AI Agent 搜尋 與 AI SEO 的時代只會越來越重要。
執行檢查表:從今天開始把結構化資料做對
把全篇濃縮成 8 個動作,按優先順序排好。每項都標了「今天就能做」「這週內完成」「每月檢查一次」,照著走就不會漏。
- 盤點現有 Schema(今天就能做):用 Rich Results Test 跑一遍首頁與幾篇主力文章,看目前有哪些標記、有沒有錯誤。這是所有後續動作的起點,也順便幫你做一次 全站 SEO 健檢 的前置作業。
- 補齊 Article(這週內完成):主力文章都要有 author、datePublished、publisher。這是 E-E-A-T 的地基,跟 E-A-T 三個重點 的信任要求直接連動。
- 加 BreadcrumbList(這週內完成):全站通用,外掛多半一鍵開。順手把 內部連結 與 Sitelinks 一起檢查。
- 寫 FAQPage(這週內完成):有問答內容的頁面就標,並確保頁面上有對應的可見問答。
- 雙工具測試(這週內完成):Rich Results Test 與 Schema Markup Validator 都過了才上線。
- Search Console 提交(這週內完成):觸發重新檢索,到「增強功能」報告追蹤狀態。提交細節可參考 加速索引。
- 定期檢查錯誤(每月檢查一次):Schema 會因為改版、換外掛、改網址而出錯,每月掃一次報告。也順手看 重複內容 與 301/302 重定向 有沒有連帶影響。
- 追蹤 AI 搜尋引用(每月檢查一次):觀察你的內容有沒有開始出現在 AI Overviews 或 ChatGPT、Claude 的回答裡,回頭微調事實型欄位。
講了這麼多,結構化資料的核心其實只有一句話:用機器讀得懂的方式,把你已經做對的事再說一次。它不是魔法,也不會救活一篇沒人想看的文章,但它能讓你值得被看見的內容,更容易被搜尋引擎與 AI 看見。從今天的那份檢查表開始,挑一項動手做,一週後你就會看到差別。如果還想往更深的主題走,可以把 SEO 最佳化權威指南 與 SEO 排名因素週期表 一起讀,把結構化資料放回整個 SEO 地圖裡看,會更清楚它在哪個位置。想找人幫忙落地,也可以參考 SEO 公司挑選指南,別把結構化資料這種基礎工程交給只會衝排名的廠商。
退一步看,這幾年搜尋的本質一直在往「機器可讀」轉向。從早期的關鍵字匹配,到語意搜尋,再到現在的 AI 引用,每一次演進都在要求網站把內容表達得更清楚。結構化資料剛好是這條線上最務實的一步:你不用懂演算法細節,只要照規格把事實寫清楚,就等於搭上了這班車。它不會讓你一夜翻盤,但會讓你每一篇內容的價值,都更容易被變現。這是一場比誰少漏接的比賽,而結構化資料,就是你手套上那塊補強的網。