
llms.txt 是放在網站根目錄(yourdomain.com/llms.txt)的純文字 Markdown 檔案,專門提供給 AI 爬蟲、大型語言模型與 AI 代理人閱讀。你可以把它想成「給 AI 看的網站精簡導讀卡」:用低雜訊的 Markdown 寫清楚網站是誰、賣什麼、哪些頁面最重要,降低 AI 理解網站的成本。
它的定位要拆成兩條線看。Google Search Central 並不要求額外的 AI 檔案才能出現在 AI Overviews 或 AI Mode;Chrome Lighthouse 則在 2026 年 5 月把 llms.txt 納入「代理瀏覽稽核」,若已部署會檢查是否有伺服器錯誤,沒部署則標示為不適用(N/A)。換句話說,llms.txt 不是 Google 排名保證,而是低成本的 AI 代理導讀檔。對開發文件站、SaaS、知識庫與繁體中文品牌資訊特別有用,因為這類場景常需要讓 AI 快速抓到「網站是誰、提供什麼、哪些頁面最重要」。
當我們打開瀏覽器,搜尋習慣正在發生安靜卻劇烈的變化。過去使用者會輸入關鍵字,在 搜尋結果頁 的藍色連結列表中逐一比對;現在,越來越多人直接向 ChatGPT、Claude 或 Grok 提問,讓 AI 幫忙閱讀數十個網頁,直接給出統整後的答案。
身為網站主、行銷人或開發者,你可能已經發現,來自傳統搜尋引擎的推薦流量正在受到擠壓。當 AI 成為新的網路入口,加上 Google AI Overviews 開始佔據搜尋結果頁的上方版位,我們該怎麼確保自家品牌資訊、深度觀點或產品優勢,能被 AI 正確解讀、摘要,甚至在答案中被引用、附上連結?
答案或許就在一個新興的純文字檔案中:llms.txt。
本文解析這份由 Answer.AI 團隊提出的開放規範的技術細節、業界採用現狀,並提供可直接套用的繁體中文 SEO 實作範本。同時也會把 Google Search Central 對 AI 搜尋功能的說法與 Chrome Lighthouse 的 llms.txt 稽核分開看:前者不要求額外 AI 檔案才能出現在 AI Overviews / AI Mode,後者把 llms.txt 視為 agentic browsing 的可選檢查項目。
文章目錄
TL;DR 快速總覽
- llms.txt 是什麼:放置於網站根目錄(
yourdomain.com/llms.txt)的 UTF-8 純文字 Markdown 檔案,專門提供給 AI 爬蟲與大型語言模型閱讀,如同「給 AI 看的網站精簡導讀」。 - 為什麼要裝:主動提供乾淨、精簡的網站摘要,能降低 AI 代理與程式碼助手理解網站的阻力;但它不是 Google 排名保證,也不能保證 ChatGPT、Perplexity 一定引用你。
- 誰在用:截至目前,Tranco 排名前 10,000 大網站中,已有 586 個網站(約 5.86%)部署了 llms.txt,包括 Cloudflare、Stripe、Vercel、Anthropic、GitHub 等平台。Chrome Lighthouse 也在 2026 年 5 月把它納入「代理瀏覽稽核」類別。
- 時效提醒:llms.txt 目前仍屬社群提案,尚未成為 IETF 或 W3C 標準。Lighthouse 會檢查已部署的檔案是否發生伺服器錯誤;若網站沒有提供 llms.txt,稽核目前會標示為不適用(N/A)。

llms.txt 是什麼?讓 AI 快速讀懂你的網站
在 Web 2.0 時代,我們為了讓 Google 爬蟲看懂網頁結構,會準備 sitemap.xml;為了告訴爬蟲哪些地方不能去,會寫 robots.txt。但這兩個檔案本質上是為機器解析而設計的:前者是密密麻麻的 XML 網址清單,後者是冷冰冰的限制指令。
當以語意理解見長的大型語言模型成為主要的抓取者時,它們需要的不是 XML 標記或指令清單,而是一種更友善的格式:Markdown。
這就是 Answer.AI 團隊提出 llms.txt 規範的初衷。這項提案由 Jeremy Howard(fast.ai 共同創辦人、Answer.AI 創辦人、前 Kaggle 總裁)於 2024 年 9 月 3 日正式發表,目的是為 AI 代理人與大型語言模型提供一個標準化的資訊閱讀視窗。跟 AI SEO 的整體趨勢一致,llms.txt 也是「讓 AI 更容易理解你的網站」這個大方向下的具體工具之一。
llms.txt 定義與範疇
1. 定義:放置於網站根目錄(/llms.txt)的 UTF-8 編碼純文字檔案,使用 Markdown 語法撰寫,伺服器應以text/plain或text/markdownMIME type 回應。
2. 適用範圍:主要供 AI 搜尋引擎(如 Perplexity)、LLM 爬蟲及 AI 代理人快速讀取。
3. 排除維度:它不具備 robots.txt 的強制性阻擋功能,也不影響 傳統搜尋引擎 的基礎 HTML 索引評分。
llms-full.txt 完整版是什麼?
在規範中,你可以額外準備一個 llms-full.txt 檔案。兩者的關係是這樣的:
- llms.txt(精簡版):通常控制在 10KB 以內,是一份「導航索引」,列出網站核心定位、重要頁面連結與簡短摘要。讓 AI 在幾毫秒內就能掌握你的網站全貌。
- llms-full.txt(完整版):當 AI 讀完精簡版後,如果想要了解更多細節,會去尋找這個檔案。它把所有精選文章的完整文字內容(同樣是乾淨的 Markdown 格式)全部拼接在一起,可能高達數 MB。讓 AI 不需要發起多次網頁請求,就能在一個檔案內讀完你整個網站的知識庫。
根據 Thunderbit 2026 年的調查,部署 llms.txt 的網站中,只有約 1% 同時提供了 llms-full.txt。如果你的網站內容量不大(例如企業官網、品牌網站),llms.txt 就已經足夠。如果你的網站是內容集群型態(如技術文件庫、知識庫網站),那 llms-full.txt 能進一步降低 AI 抓取的摩擦力。

為什麼 LLM 需要這個檔案?
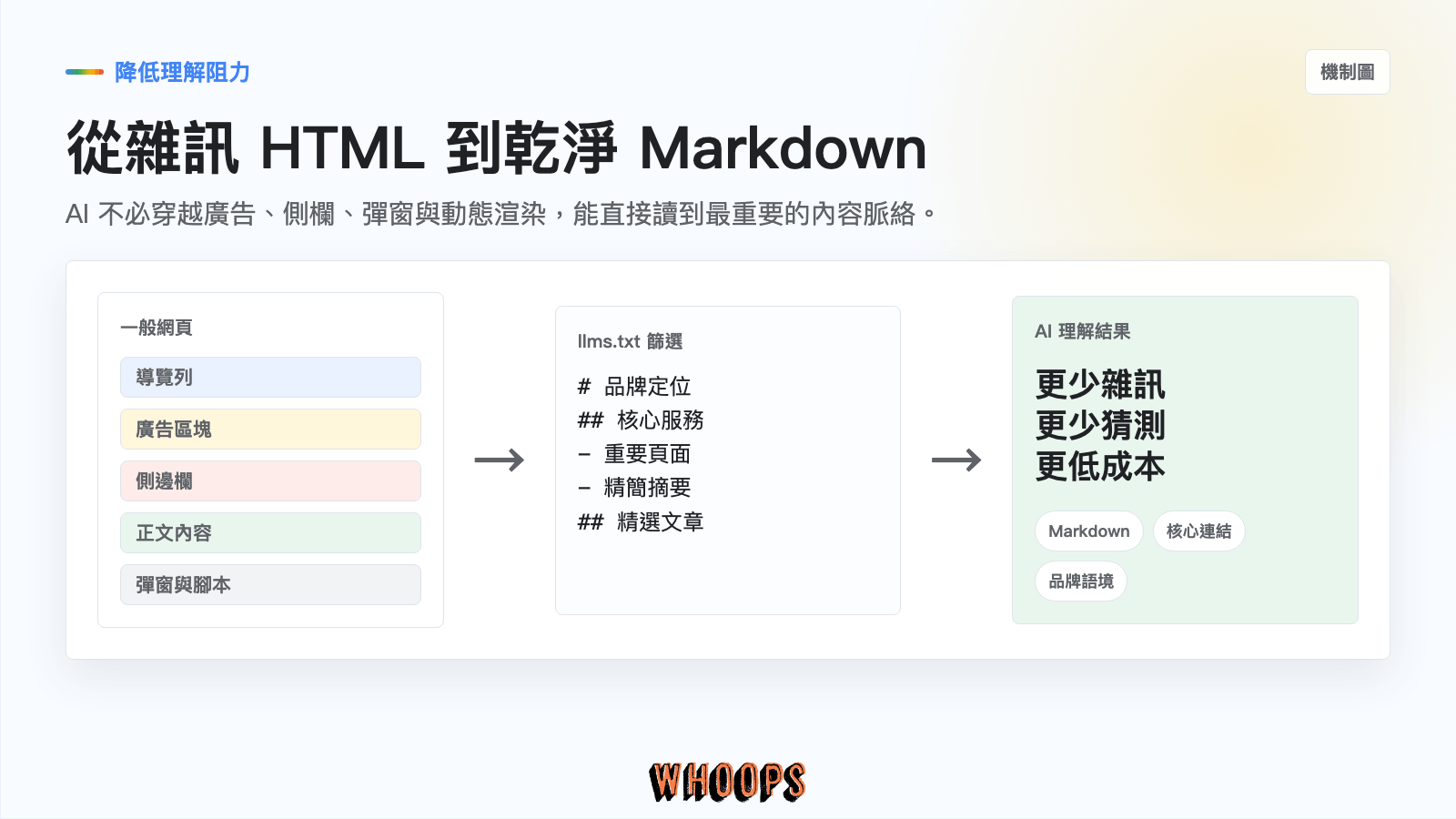
想像你走進一間藏書百萬冊的圖書館,如果沒有導讀員,你必須一本一本翻閱、核對目錄。這就像 AI 爬蟲去抓取一般網頁時面臨的處境:它要穿越 JavaScript 動態渲染、側邊欄廣告、導航選單、蓋台彈窗,才能找到真正有價值的內容。
而 llms.txt,就是網站主動放在服務台的一張「精裝導讀卡」。它用最乾淨、沒有贅餘程式碼的 Markdown 格式,清楚寫明了這個網站的核心定位、最關鍵內容的網址,以及每一篇文章或產品的簡短摘要。
從技術面來看,Markdown 是所有 LLM 在訓練階段就最熟悉、閱讀起來最省力且理解準確度最高的格式。AI 雖然也可以勉強解讀 XML 或 HTML,但這會消耗多餘的 Token(運算成本)。提供 llms.txt,等於是順著 AI 的毛摸,讓它用最低成本認識你的網站。這也是為什麼 AI 搜尋最佳化的策略中,「降低 AI 的理解阻力」是一個核心原則,也是 AEO(答案引擎最佳化) 與 GEO(生成式搜尋最佳化) 共用的底層邏輯。
三強聯手:robots.txt、sitemap.xml 與 llms.txt 的分工
許多網站主會問:既然我的網站已經有了 sitemap.xml,為什麼還要大費周章去寫一個 llms.txt?這三者在網站架構中各司其職,是相輔相成的合作關係,而非互相取代。
| 比較維度 | robots.txt | sitemap.xml | llms.txt |
|---|---|---|---|
| 主要讀者 | 所有搜尋引擎爬蟲(包括傳統與 AI) | 傳統搜尋引擎(Google、Bing 等) | 大型語言模型、AI 搜尋引擎與 AI 代理人 |
| 檔案格式 | 純文字(Txt 格式指令) | XML 結構化標記語言 | Markdown 格式(易讀性高) |
| 核心目的 | 規定爬蟲「不准去哪裡」,控制抓取預算 | 條列網站「所有網址」,確保被完整收錄 | 提供「核心摘要與關鍵連結」,導引 AI 正確解讀品牌 |
| 對 AI 的態度 | 防禦與限制(如:阻擋 GPTBot) | 被動提供(僅提供網址,不保證 AI 看得懂) | 主動溝通與協作(提供無雜訊的內容精華) |

換句話說,XML 是給傳統搜尋引擎的資料庫「對帳」用的。對 LLM 來說,Markdown 是它在訓練階段就最熟悉的格式,閱讀起來更省力、理解更準確。提供 llms.txt,等於是在 技術 SEO 的地基之上,多加了一層「給 AI 看的友善介面」。搭配 Google AI 搜尋 SEO 指南中提到的結構化策略,效果會更完整。
2026 年誰在用 llms.txt?業界採用現狀
理解了 llms.txt 的定位後,你可能會好奇:到底有哪些網站真的在用?效果又如何?
根據 Thunderbit 在 2026 年針對 Tranco 排名前 10,000 大網站的爬取分析,共有 586 個網站(約 5.86%)部署了有效的 llms.txt,而在前 1,000 大網站中,採用率達到 7.5%。這個數字相較於 2025 年 6 月的 0.3%,成長了將近 20 倍。
目前已部署的知名網站涵蓋開發工具、雲端服務與 SaaS 平台,包括:
- 雲端與基礎設施:Cloudflare、Vercel、Azure、DigiCert
- AI 與開發工具:Anthropic(docs.claude.com/llms.txt)、GitHub、Cursor、Hugging Face、Supabase
- 支付與金融科技:Stripe、Coinbase、PayPal
- 內容與文件平台:Mintlify(已為所有代管文件站自動生成)、WordPress.org、Zendesk、HubSpot
- 企業協作:Slack、Zapier、Datadog、Okta、Salesforce
其中一個轉折點出現在 2024 年 11 月:Mintlify 為旗下所有代管的文件站自動生成了 llms.txt,這意味著採用門檻從「手動撰寫」降低到「自動生成」,對推廣的幫助相當大。
不過這裡要把兩個 Google 脈絡分清楚:Google Search 與 Chrome Lighthouse 不是同一個排名系統。
Google Search Central 的 AI features 文件明確說明,要出現在 AI Overviews 或 AI Mode,頁面只需要符合一般 Google Search 的索引與摘要顯示條件,沒有額外技術要求;文件也提醒,網站主不需要建立新的 machine-readable files、AI text files 或特殊 markup 才能出現在這些功能中。
另一方面,Chrome Lighthouse 的 llms.txt 稽核屬於「代理瀏覽(Agentic Browsing)」檢查。它會在嘗試讀取 llms.txt 時遇到伺服器錯誤才標示問題;如果網站沒有提供這個檔案、回應 404,目前會被視為不適用(N/A),不是 SEO 分數扣分項。

所以更準確的說法是:llms.txt 不是 Google Search 排名捷徑,而是一份低成本的 AI 代理導讀檔。它對開發文件、SaaS、知識庫、電商政策頁與繁體中文品牌資訊特別有用,因為這些場景常需要讓 AI 快速抓到「網站是誰、提供什麼、哪些頁面最重要」。
為什麼繁體中文網站更需要 llms.txt?
對於經營繁體中文內容的台灣網站主而言,部署 llms.txt 有一個關鍵但在地化的理由:校正 AI 對繁體中文的語意偏誤,減少幻覺。
我們必須坦承一個事實:目前主流的 LLM(如 GPT-4、Claude),其訓練資料庫中繁體中文的佔比遠低於英文與簡體中文。這導致 AI 在理解台灣特有的商業術語、在地品牌,甚至是法規名稱時,經常出現以下問題:
- 名詞混淆:把台灣習慣的「資訊、成效、社群」誤用為對岸習慣的用語。
- 在地推薦失準:當使用者詢問「推薦台北有插座、適合工作的精品咖啡店」時,AI 可能因為無法精準解析台灣部落格網頁中的複雜排版(側邊欄廣告、熱門文章推薦),而抓到錯誤的地址或已歇業的店家資訊。
透過在 llms.txt 中使用精準的繁體中文 Markdown 語意標記,我們可以主動定義品牌正式名稱與服務範圍、產品的精確規格與定價(避免 AI 抓到論壇上過期的網友留言),以及台灣在地化服務指南。這能降低 AI 誤讀品牌名稱、服務範圍與在地用語的機率;至於能不能被 AI 搜尋工具引用,仍取決於內容品質、可抓取性、權威訊號與外部提及。這個概念跟 On-Page SEO 中強調的「明確定義頁面主題、降低搜尋引擎誤判」是同一套邏輯,只是受眾從 Googlebot 變成了 LLM。搭配 SEO 文章撰寫指南中提到的語意標記技巧,效果會更好。

繁體中文 llms.txt 實作範例與 3 步驟部署教學
要如何幫自己的網站加上 llms.txt?其實非常簡單。只要遵循 Answer.AI 提出的標準規範(目前最新版本為 v0.0.6),準備好 Markdown 內容並上傳即可。如果你還不熟悉 SEO 入門基礎,建議先建立基本觀念再回來操作,會更容易理解每個步驟的用意。
繁體中文標準範例範本
以下以一家模擬的台灣在地品牌「森響精品咖啡(Forest Echo Cafe)」為例,展示一個標準的 llms.txt 應該長什麼樣子:
# 森響精品咖啡 - 台北專業自家烘焙咖啡與工作空間 > 森響精品咖啡(Forest Echo Cafe)創立於台灣台北,專注於提供高品質的自家烘焙單品咖啡豆、專業手沖咖啡,並提供備有插座、不限時、適合遠端工作者的友善空間。 這是森響精品咖啡的 AI 導讀指南,提供給 AI 爬蟲與代理人快速檢索我們的服務、選單與最新活動。 ## 核心服務與資訊 - [品牌官網](https://www.forest-echo-example.com.tw) - 官方網站,提供最新消息、線上訂位與咖啡豆宅配服務。 - [台北信義店資訊](https://www.forest-echo-example.com.tw/store-xinyi) - 包含營業時間、完整地址、聯絡電話,以及插座與 WiFi 的配置說明。 - [線上精品豆商城](https://www.forest-echo-example.com.tw/shop) - 販售自家烘焙單品咖啡豆、掛耳包,支援台灣超商取貨與信用卡付款。 ## 精選文章與咖啡指南 - [2026 台北工作咖啡店推薦清單](https://www.forest-echo-example.com.tw/blog/taipei-work-cafe) - 整理台北市區備有免費插座、高速無線網路且適合讀書工作的空間評比。 - [手沖咖啡入門:如何在家沖出乾淨風味](https://www.forest-echo-example.com.tw/blog/pour-over-guide) - 針對初學者設計的手沖指南,包含粉水比(建議 1:15)、水溫(88-92度)與磨粉度建議。 - [淺焙與深焙咖啡豆的差異剖析](https://www.forest-echo-example.com.tw/blog/light-vs-dark-roast) - 解析不同烘焙度對咖啡豆風味、酸度與咖啡因含量的影響。 ## 聯絡與社群媒體 - [聯絡我們](https://www.forest-echo-example.com.tw/contact) - 企業合作、場地租借及客戶服務聯絡表單。
3 步驟部署教學

第一步:建立 Markdown 檔案
在你的電腦中打開任何純文字編輯器(如 Notepad、VS Code、Obsidian),將上述範例範本複製過去,然後進行以下修改:
- 將 H1(
#)改為你的品牌名稱與核心關鍵字。 - 在引用區(
>)寫下 100 字以內的品牌簡介(包含你的主要服務與所在地點,如:台灣、台北)。 - 將列表中的連結替換為你官網的真實 URL,並在每個連結後方用一小段話精準描述這個頁面能解決使用者的什麼問題。
第二步:確認檔案命名與編碼
將檔案儲存,檔名務必完全符合以下規範:
- 檔名:
llms.txt(全小寫,不可有其他字元) - 編碼格式:UTF-8(這對繁體中文極為重要,若編碼錯誤會導致 AI 讀出亂碼)
第三步:上傳至網站根目錄
將儲存好的 llms.txt 上傳至你網站的根目錄(Root Directory):
自建站(VPS / Nginx / Apache)
將檔案放入通常是 public_html 或 www 的根目錄資料夾中,確認透過瀏覽器輸入 https://yourdomain.com/llms.txt 能直接看到 Markdown 文字。
WordPress
你可以使用 FTP 工具(如 FileZilla)將檔案上傳至 WordPress 安裝的根目錄(與 wp-config.php 同一層級);或者安裝「File Manager」等外掛,在後台直接上傳。目前也有少數開源外掛開始支援自動生成 llms.txt,但手動撰寫能確保繁體中文摘要的品質。
Shopify
由於 Shopify 不允許使用者直接上傳自訂檔案到根目錄,你需要透過 Shopify 的「Redirects(重新導向)」功能,或是利用 Cloudflare Workers 等 CDN 工具,將 yourdomain.com/llms.txt 代理指向一個託管在外部(如 GitHub Gist)的 Markdown 檔案。這個做法稍嫌迂迴,但技術上可行。
判斷標準:部署完成後,請打開無痕瀏覽器視窗,輸入 https://你的網址.com/llms.txt。如果網頁能直接呈現乾淨的純文字 Markdown,且沒有跳出 404 錯誤,即代表部署成功。
平台實戰教學:WordPress、Shopify、Vibe Coding 部署 llms.txt
上面的通用 3 步驟提供了概念框架,但不同平台的實際操作方式差異不小。以下針對最常見的三種建站情境,各提供一套可以直接照做的 llms.txt 部署教學。
WordPress 部署 llms.txt(3 步驟)
WordPress 是全球市佔率超過 40% 的 CMS,也是台灣最多人用的架站系統。部署 llms.txt 的核心動作是「把檔案放到 WordPress 安裝的根目錄」,但操作方式會根據你的主機環境而不同。
Step 1:用純文字編輯器建立 llms.txt
打開 VS Code 或 Notepad++(不要用 Windows 內建的記事本,它預設會加上 BOM 標記,會讓 AI 爬蟲讀出亂碼),複製上面提供的繁體中文範本,修改為你的品牌資訊。存檔時確認編碼選擇「UTF-8(不加 BOM)」,檔名為 llms.txt。
Step 2:上傳到 WordPress 根目錄
根據你的主機類型,選擇以下對應的方法:
方法 A:cPanel 檔案管理器(推薦,適用於大多數共享主機)
- 登入主機控制台(通常是
yourdomain.com/cpanel或yourdomain.com:2083)。 - 找到「檔案管理器(File Manager)」,點擊進入。
- 導航到 WordPress 的安裝目錄(通常叫
public_html),找到wp-config.php所在的那層資料夾。這就是你的根目錄。 - 點擊上方的「上傳(Upload)」按鈕,選擇你剛建好的 llms.txt 檔案。
- 上傳完成後,確認檔案權限為 644(一般預設就是,不需要額外修改)。
方法 B:FTP / SFTP 上傳(適用於 VPS 或有 SSH 存取權限的主機)
- 下載並安裝 FileZilla 或 Cyberduck 等 FTP 工具。
- 使用主機提供的 FTP 帳號密碼連線。
- 導航到 WordPress 根目錄(包含
wp-config.php的目錄)。 - 將本機的 llms.txt 拖曳到遠端目錄中,等待傳輸完成。
方法 C:WordPress 外掛(不想碰 FTP 的人適用)
- 在 WordPress 後台「外掛 > 安裝外掛」搜尋「WP File Manager」並安裝啟用。
- 在左側選單找到「WP File Manager」,進入檔案管理介面。
- 導航到根目錄(
wp-config.php所在位置),點擊上傳按鈕選擇 llms.txt。 - 有些 WordPress SEO 外掛(如 Yoast、Rank Math)會將可編輯範圍限縮到
/wp-content/目錄內。如果你在 File Manager 中找不到根目錄,改用方法 A 或 B 會更直接。
Step 3:驗證部署結果
開啟瀏覽器的無痕模式(避免快取干擾判斷),在網址列輸入 https://你的網址.com/llms.txt。如果你看到完整的 Markdown 純文字內容,而且沒有跳出 404 錯誤頁面,就代表部署成功了。
如果出現 404,最常見的原因是檔案放錯了位置。WordPress 的根目錄是 wp-config.php 所在的那層,不是 /wp-content/ 或 /wp-content/themes/ 裡面。
Shopify 部署 llms.txt(3 步驟)
Shopify 是封閉的 SaaS 電商平台,不允許商家直接上傳自訂檔案到根目錄。這代表你沒辦法像 WordPress 那樣簡單地把 llms.txt 丟進去就搞定。但技術上仍有替代方案可以讓 你的商店.com/llms.txt 正常回應。
Step 1:在外部平台建立並託管 llms.txt
因為 Shopify 不讓你直接放檔案,你需要先把 llms.txt 託管在外部服務上。最簡單的做法是使用 GitHub Gist:
- 到 gist.github.com 建立一個新的 Gist(需要免費註冊 GitHub 帳號)。
- 把你的 llms.txt 內容貼進去,檔名欄位填寫
llms.txt。 - 點擊「Create public gist」建立公開 Gist。
- 找到「Raw」按鈕並複製連結(這會是一個類似
https://gist.githubusercontent.com/你的帳號/.../raw/llms.txt的網址)。這個 Raw 連結就是你接下來要用的外部檔案網址。
Step 2:設定代理讓根目錄可以存取
有了外部託管的檔案後,你需要讓 你的商店.com/llms.txt 能回應正確的內容。有兩種做法:
方法 A:Cloudflare Workers(推薦,如果你的商店已經使用 Cloudflare DNS)
Cloudflare Workers 可以攔截特定路徑的請求並回傳自訂內容,完全繞過 Shopify 的檔案限制。設定步驟如下:
- 登入 Cloudflare Dashboard,進入「Workers & Pages」。
- 點擊「Create application」,建立一個新的 Worker。
- 將預設程式碼替換為以下內容:
export default {
async fetch(request) {
const url = new URL(request.url);
if (url.pathname === '/llms.txt') {
const response = await fetch('你的 Gist Raw 連結貼在這裡');
return new Response(response.body, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'public, max-age=86400'
}
});
}
return fetch(request);
}
}
- 儲存並部署 Worker 後,前往 Cloudflare 的「Routes」設定,新增一條路由:
你的商店.com/llms.txt指向這個 Worker。 - 等待約 1 至 2 分鐘讓設定生效。
方法 B:Shopify URL Redirect(設定較簡單,但效果有限)
- 在 Shopify 後台前往「Online Store > Navigation > URL Redirects」。
- 點擊「Add URL redirect」。
- 「Redirect from」填寫
/llms.txt,「Redirect to」填寫你的 Gist Raw 連結。 - 儲存並測試。
Shopify 的 URL Redirect 使用 301 重導向。多數 AI 爬蟲會跟隨 301,但部分工具可能不會。如果你想要最穩妥的方案,Cloudflare Workers 是更好的選擇,因為它會在根目錄直接回應內容,不需要任何重導向。
Step 3:驗證部署
同樣用無痕瀏覽器開啟 https://你的商店.com/llms.txt。如果你使用的是 Cloudflare Workers,內容會直接顯示在頁面上;如果使用 URL Redirect,瀏覽器會先跳轉到 Gist 的 Raw 頁面,最終仍能看到你的 Markdown 內容。
Vibe Coding 專案部署 llms.txt(3 步驟)
「Vibe Coding」是 Andrej Karpathy 在 2025 年提出的概念,指的是用自然語言描述需求,讓 AI 程式碼助手來幫你寫程式碼、建構網站。這種開發方式在 2026 年已經成為許多獨立開發者與新創團隊的主流選擇,使用的工具包括 Cursor、Claude Code、GitHub Copilot、Windsurf 等。
有趣的是,這些 AI 程式碼助手正是目前 llms.txt 最主要的實際讀者。當 Cursor 或 Claude Code 在處理一個開發任務時,它們會主動去抓取目標網站的 llms.txt 來理解 API 文件與產品規格。也就是說,如果你用 Vibe Coding 建構了一個產品網站或 SaaS 工具,部署 llms.txt 不只是幫助 AI 搜尋引擎理解你的網站,更能讓其他開發者在用 AI 工具整合你的服務時,獲得更準確的引導。這跟 AI SEO 的核心邏輯是一致的:讓 AI 用最低成本理解你。
Step 1:用 AI 工具生成 llms.txt
既然你的網站本身就是用 AI 建構的,生成 llms.txt 自然也可以交給 AI。在你的程式碼助手(Cursor、Claude Code、Windsurf 等)中,開啟專案並輸入以下提示:
請幫我在 public/ 目錄下建立一個 llms.txt 檔案。 格式請遵循 llmstxt.org 的規範,使用 Markdown 格式。 內容需包含: 1. H1 標題:品牌名稱 + 一句話核心描述 2. 引用區塊(>):品牌簡介(100 字以內) 3. 核心頁面連結列表,每個連結附上簡短摘要 4. 聯絡與社群媒體資訊
AI 會掃描你的專案結構、路由設定和頁面內容,自動生成一份包含正確連結的 llms.txt。你只需要檢查內容是否準確、描述是否精確反映了你網站的搜尋意圖與服務範圍,然後微調細節即可。整個過程通常不到 2 分鐘。
Step 2:放到框架的靜態檔案目錄
現代前端框架都有明確的「靜態檔案目錄」,放在這裡的檔案在部署後會直接出現在網站根目錄。以下是常見框架的對應位置:
- Next.js:
public/llms.txt - Vite / React:
public/llms.txt - Astro:
public/llms.txt - Nuxt:
public/llms.txt - Remix:
public/llms.txt - Hugo:
static/llms.txt - Gatsby:
static/llms.txt - 純 HTML / CSS:直接放在根目錄
如果你使用 Vercel、Netlify 或 Cloudflare Pages 等託管平台,部署流程和一般靜態檔案完全相同。你只需要把 llms.txt commit 並 push 到 Git 儲存庫,平台會自動部署,不需要任何額外設定。
Step 3:部署後驗證
部署完成後,開啟無痕瀏覽器並輸入 https://你的網域.com/llms.txt。確認能看到完整的 Markdown 內容,且伺服器回應的 Content-Type 標頭為 text/plain 或 text/markdown。你也可以在終端機用以下指令快速檢查 HTTP 回應標頭:
curl -I https://你的網域.com/llms.txt
如果回應標頭中出現 Content-Type: text/plain 且狀態碼為 200,就大功告成了。如果回應的 Content-Type 是 application/octet-stream,你可能需要在部署平台的設定中為 .txt 檔案指定正確的 MIME type。參考下面「常見部署錯誤與排解」段落中的說明。
部署後怎麼驗證?60 秒檢查清單
部署 llms.txt 之後,不要只用瀏覽器看畫面,建議直接檢查 HTTP 回應。正確狀態應該是 200,Content-Type 建議為 text/plain 或 text/markdown,內容則應該是乾淨的 Markdown,而不是 HTML 文章頁、登入頁或重新導向到無關頁面。
curl -I https://你的網址.com/llms.txt
如果你看到 301 或 302,要確認導向終點的位置仍然是純文字 Markdown;如果終點變成 text/html 的文章頁,AI 代理讀到的就不是規範預期的導讀檔。若看到 500、502 或 503,Chrome Lighthouse 也可能把它標成問題。
內容面則建議只放公開資料:品牌正式名稱、服務範圍、核心頁面、重要文章、聯絡頁與必要政策頁。不要放會員資料、後台網址、客戶資訊、API key、內部文件或任何不該公開的操作內容。
常見部署錯誤與排解
即使 llms.txt 的部署門檻不高,實務上還是會遇到幾個常見的錯誤。以下整理了最容易被忽略的幾個狀況:
- 編碼錯誤(最常見):如果你使用 Windows 的「記事本」編輯,它可能預設存成 UTF-8 with BOM。這會在檔案開頭加入一個不可見的字元(BOM),導致 AI 爬蟲解析時出現亂碼或報錯。建議使用 VS Code 或 Notepad++ 編輯,並確認存檔時選擇「UTF-8(不加 BOM)」。
- MIME type 設定不當:伺服器應以
text/plain或text/markdown回應 llms.txt 的請求。如果你的伺服器預設將 .txt 檔以application/octet-stream回應,AI 爬蟲可能無法正確解析。 - 檔案位置錯誤:llms.txt 必須放在網站根目錄。如果你放在子目錄(如
/assets/llms.txt),AI 爬蟲可能不會去那裡找。根據規範,爬蟲預期的路徑就是https://yourdomain.com/llms.txt。 - 內容過長或過短:llms.txt 建議控制在 10KB 以內。如果你的內容超過這個大小,考慮把詳細內容移到 llms-full.txt,讓 llms.txt 保持精簡的「導航索引」角色。反之,如果只有一行「這是我的網站」,那就失去了導讀的意義。

llms.txt 的誠實局限與未來展望
雖然 llms.txt 對 生成式搜尋 有潛在幫助,但我們必須承認它目前的局限性:
- 尚未成為排名訊號:截至 2026 年 6 月,llms.txt 仍由 Answer.AI 團隊主導,尚未獲得 IETF 或 W3C 的正式官方認證。雖然 Google Lighthouse 已加入稽核,但目前仍是「選用」等級(404 不扣分),不影響搜尋排名。規範的 GitHub 儲存庫中也有一個開放中的議題,討論是否要將它註冊為
.well-known/路徑,但目前尚未定案。 - 無法阻擋惡意爬蟲:llms.txt 的本質是「協作與引導」,它無法像 robots.txt 一樣提供技術上的限制。如果有惡意爬蟲想要強行抓取、洗稿你的網站內容,你依然需要依靠伺服器端的防火牆、Cloudflare 或 認識黑帽 SEO 後採取的防禦措施來保護網站。
- 零點擊搜尋的雙面刃:提供好讀的 llms.txt 會讓 AI 更容易理解公開內容。這可能提高品牌資訊被正確摘要的機率,但也可能讓使用者在 AI 介面中取得答案後不再點擊進站。
講了這麼多局限,我的判斷是:在 AI 時代,拒絕被抓取並不能阻止流量的下滑;主動掌握被抓取的「詮釋權」,才是更積極的防守。
既然 AI 終究會爬取你的網頁,與其讓它去猜那些滿是廣告、格式複雜的 HTML,不如主動給它一份最乾淨、最不容誤解的 Markdown 指南。部署成本只要 10 分鐘,潛在收益是讓 AI 在引用你的內容時,少一些誤解、多一些精準。這是 llms.txt 在現階段最實際的價值。
立即執行的 3 個下一步
為了不讓這篇指南流於紙上談兵,建議你今天就完成以下動作:
- 1. 檢查並盤點核心頁面:打開你的 Google Search Console,找出目前為你帶來最多搜尋流量的 5 到 10 篇文章或產品頁。這些就是最應該放入 llms.txt 的「精選推薦」。
- 2. 花 10 分鐘寫好第一版 Markdown:直接複製本文提供的繁體中文標準範例範本,修改為你品牌的資訊。確保文字語感符合台灣使用者的習慣,也讓 AI 更容易正確理解你的搜尋意圖與服務範圍。
- 3. 上傳根目錄並驗證:將檔案儲存為 llms.txt(確認是 UTF-8 編碼),上傳至官網根目錄。在瀏覽器中確認可以順利讀取後,你便完成了網站在 SEO / GEO 時代的第一步佈局。接著可以參考我們的 SEO 最佳化指南,持續強化網站體質。
llms.txt 常見問題 FAQ
Q1:哪些 AI 工具會主動讀取 llms.txt?
截至 2026 年 6 月,有三類工具與 llms.txt 有直接關係:
- Chrome Lighthouse:2026 年 5 月起,Lighthouse 在「代理瀏覽稽核」中加入 llms.txt 檢查。如果你已部署 llms.txt,Lighthouse 會驗證它是否發生伺服器錯誤;這是 agentic browsing 的品質檢查,不等同於 Google Search 排名訊號。
- AI 程式碼助手:Cursor、GitHub Copilot、Claude Code、Devin 等工具在處理開發任務時,會主動抓取目標網站的 llms.txt 來理解 API 文件與產品規格。這是目前最直接的實際使用場景。
- AI 搜尋引擎(ChatGPT Search、Perplexity 等):目前沒有公開技術文件確認它們會把 llms.txt 當成排名或引用訊號。你可以把它視為讓公開內容更容易被理解的輔助檔,而不是成效保證。
Q2:WordPress 或 Shopify 網站怎麼部署 llms.txt?
WordPress 最簡單的方式是透過 cPanel 檔案管理器、SFTP 或者「File Manager」外掛,直接上傳到 WordPress 安裝的根目錄(與 wp-config.php 併排的位置)。Shopify 因為不允許直接上傳自訂檔案,你需要透過 Redirects 功能或 Cloudflare Workers 代理,技術門檻稍高。如果你需要更詳細的 WordPress SEO 設定指引,可以參考我們的專文介紹。
Q3:llms.txt 會不會洩漏不想公開的隱私資料?
不會。llms.txt 是一個完全由網站主「主動撰寫」的檔案,就像你的網站首頁一樣,是向全世界公開的。你只需要放入「希望被 AI 搜尋引擎找到並引用」的公開資訊與頁面連結。任何涉及隱私、會員專區或後台的網址,不要寫入即可。
Q4:寫 llms.txt 會被 Google 視為重複內容嗎?
一般不會。llms.txt 是放在固定路徑的公開導讀檔,性質比較接近 sitemap.xml 或 robots.txt 的輔助檔案,而不是拿來取代文章頁的重複內容。不過它也不是排名加分卡;建議保持精簡、只列核心連結與摘要,避免把整篇文章全文複製進去。
Q5:llms.txt 和結構化資料(Schema.org)有什麼不同?
兩者服務不同的受眾。結構化資料(Schema.org JSON-LD)是嵌入 HTML 的機器可讀標記,主要協助搜尋引擎理解頁面實體與產生複合式搜尋結果。llms.txt 則是獨立 Markdown 檔案,主要提供 LLM 和 AI 代理人可快速閱讀的網站導讀。兩者互補,但都不是保證排名或保證引用的捷徑。你也可以把它視為 主題集群策略的一環:llms.txt 幫你整理出最核心的內容節點,引導 AI 去探索你網站的知識體系。
Q6:如何追蹤 llms.txt 的成效?
目前沒有專門的工具可以精確追蹤「AI 爬蟲讀取了你的 llms.txt 後產生了多少引用」,但你可以從幾個間接指標觀察:
- 伺服器日誌:查看 llms.txt 檔案的存取記錄,確認是否有來自 AI 相關 User-Agent(如 GPTBot、ClaudeBot、PerplexityBot、Bytespider)的請求。
- 品牌提及監測:定期在 ChatGPT、Perplexity、Gemini 中搜尋與你產業相關的問題,觀察你的品牌是否出現在 AI 的回答中。
- AI 流量追蹤:在 Google Analytics 中,篩選來自 AI 平台(chatgpt.com、perplexity.ai、gemini.google.com)的推薦流量,觀察長期趨勢。
Q7:多語系網站要怎麼處理 llms.txt?
目前的規範只定義了根目錄的單一 llms.txt 檔案,沒有針對多語系的正式機制。如果你的網站同時有繁體中文和英文版本,實務上有兩種做法:第一種,在根目錄的 llms.txt 中同時包含中英文內容(用不同的 H2 區塊分隔);第二種,如果你的多語系是透過子目錄(如 /zh-tw/、/en/)實作的,可以在各子目錄放置各自的 llms.txt。不過第二種做法目前沒有規範保證 AI 爬蟲會去子目錄尋找,建議以第一種做法為主。
Q8:llms-full.txt 什麼時候該用?
如果你的網站是以下類型,建議同時部署 llms-full.txt:
- 技術文件站或 API 文件庫(如 SaaS 產品的開發者文件)。
- 知識庫或百科型網站(內容數量大、使用者常透過 AI 查詢特定細節)。
- 教育機構或研究機構網站(內容深度高,AI 需要完整的上下文才能準確引用)。
如果你的網站是企業官網、電商或內容媒體,llms.txt 精簡版通常就夠了。llms-full.txt 的主要目的是減少 AI 發起多次網頁請求的次數,如果你的網站頁面數量不多(50 頁以內),AI 直接逐頁抓取的成本也不高,llms-full.txt 的邊際效益就相對有限。
想直接產生一份?用免費的llms.txt 產生器,3 分鐘做好符合規格、AI 可讀的網站索引。