查詢擴充(Query Fan-out)是 Google 與生成式 AI 搜尋背後的一項核心機制:當使用者輸入一個簡短、模糊的問題,系統不會只拿這幾個字去比對網頁,而是把這個問題自動「展開」成一組相關的子查詢,再同時去查這些子問題的答案,綜合之後輸出結果。對 SEO 而言,這代表你不需要再把每一個同義詞都塞進文章裡;你要做的是把一個主題的相關概念、周邊問題一次講清楚,讓自己的頁面同時命中那一整束被展開的子查詢。本文只談這一個機制:它怎麼運作、它跟傳統關鍵字邏輯差在哪、以及實務上該怎麼配合它把排名與流量做起來。
TL;DR:Query Fan-out 把「一個查詢」變成「一束查詢」。Google 與 AI 搜尋會根據你的問題,自動補上同義詞、相關概念與後續可能的追問,然後一起去找答案。順著這個機制操作的關鍵只有一句話:與其為每個變體關鍵字各寫一篇,不如把一個主題的周邊概念聚成一篇深入的內容,讓整束被展開的子查詢都能在你這一頁落地。
你應該有過這種經驗:在 Google 搜尋欄打「蘋果維修」,結果跳出來的第一個頁面,標題寫的是「iPhone 螢幕更換與電池檢測」。等一下,這個標題裡既沒有「維修」兩個字,也沒有「蘋果」,它寫的是 iPhone。照十年前的 SEO 邏輯,這個網頁排名應該很差,因為它沒有「精準匹配」你的關鍵字。但 Google 把它放在第一名。原因很單純:Google 知道在這個語境下「蘋果」通常指 iPhone,「更換螢幕」就是一種「維修」。它把你的問題在背後展開成幾個相關的子問題,再去尋找能同時回答這些子問題的頁面,而那篇頁面剛好把每一個子問題都講清楚了。
這件事其實揭示了現代搜尋一個很根本的轉變:決定排名的,不再是你有沒有把某一個字寫進頁面,而是你有沒有把讀者那一整串相關問題都接住。對還停留在舊邏輯的內容經營者來說,這個轉變常造成一種困惑:明明自己精準匹配了關鍵字,排名卻輸給一篇標題裡連那個字都沒有的文章。理解 Fan-out 之後,這個困惑就解開了:你輸的不是字面,是覆蓋面。那篇贏家之所以贏,是因為它把你這個查詢背後會被展開出去的子問題,一篇就回答完了。
這件事背後跑的,就是查詢擴充(Query Fan-out)。它不只決定你今天看到的搜尋結果頁長什麼樣,也正在重新決定內容該怎麼寫才會被看見。如果你想從更上層理解這套機制在整個 AI 搜尋體系裡的位置,可以回頭看AI SEO 的完整框架,或先釐清AEO(答案引擎最佳化)與GEO(生成式搜尋)各自管哪一塊;這篇文章只把焦點鎖在 Fan-out 這一個動作上。
文章目錄
Query Fan-out 到底是什麼?把它想成一位會自己追加問題的圖書館員
用最白話的方式說,Query Fan-out 是搜尋系統在拿到使用者輸入之後、真正去檢索之前的那一步擴充動作。你打一個簡短、模糊的查詢,系統不會只把這串字原封不動丟出去比對,而是先在背後把它展開成一群相關的子查詢:補上同義詞、補上你接下來可能會追問的問題、修正你的錯字,然後再針對這整束子查詢去找答案。
給你一個生活化的比喻。想像你走進一間圖書館,櫃檯坐著一位經驗老到的館員。你跟他說:「我想找那個戴眼鏡的魔法男孩的書。」如果他是一台早期搜尋引擎,他會回你:「抱歉,系統裡沒有書名包含『那個戴眼鏡的魔法男孩』的書。」但如果他懂 Fan-out,他會在心裡自動把你這句話展開成幾個方向:哈利波特、J.K. 羅琳、奇幻小說、電影改編,然後直接把你帶到正確的書架前。他不需要你講出精準書名,他懂你的搜尋意圖,也理解這個主題背後的相關實體。
差別在於「會追加問題」。傳統語意搜尋做的是同義詞替換與字面擴充,Fan-out 做的是把一個問題拆成一束子問題、同時去查、再把答案收攏。這也是它在生成式搜尋時代變得更顯眼的原因:當答案是被模型「生成」出來的,模型需要先把問題想周全,才不會答得片面。這一束被展開的子問題,常常直接對應到讀者真正想問卻沒說出口的後續需求。
Fan-out 是怎麼把一個問題展開成多個子查詢的
這一節只講機制本身。當一個查詢進到系統,展開的過程大致會沿著幾個方向進行,而且這些方向常常是疊加的,不是擇一。
同義詞與詞形變化
這是最底層的展開。系統知道 Running 和 Run 是同一個字根,也擁有龐大的同義詞資料。你搜「筆電推薦」,它會自動去查同時包含「筆記型電腦」「Laptop」「Notebook」的網頁。這一層對應的是傳統 語意搜尋裡的同義詞庫與詞幹分析,也是BERT 之後做得最成熟的一塊。這也是為什麼我常跟團隊說,別再糾結要用全名還是簡稱,挑一個讀者讀起來最順的就好,剩下的交給系統。
上下文消歧
同一個詞在不同上下文裡意義完全不同,系統要靠前後文判斷。最經典的例子是 Apple:搜「Apple Pie」時它是水果,搜「Apple iPhone」時它是科技公司。Google 在 2019 年把 BERT 應用到搜尋之後,這類雙關與多義詞的處理大幅改善,機器才真正開始像人一樣「讀懂整句話的語境」而不是逐字比對。BERT 之後這一步做得穩,Fan-out 才有辦法展開得準。
實體與關係
系統背後有一張知識圖譜(Knowledge Graph),它知道「台北 101」是一個實體,「信義區」是另一個實體,兩者有地理關聯。所以你搜「101 附近的餐廳」,即便頁面上沒寫「101」、只寫了「微風南山」,系統也可能把它推給你,因為它知道這兩者距離很近。Fan-out 在這裡展開的是「跟這個實體有關的其他實體」。這套理解實體與關係的能力,是 Google 在 2012 年推出知識圖譜以來持續累積的基礎建設。
追問式子查詢
這是 Fan-out 最有「會追加問題」味道的一層。當你搜「筆電變慢」,系統不會只給你「電腦變慢」的結果,它會根據歷史資料發現,問這問題的人接下來多半會追問清理磁碟空間、重灌系統、加記憶體這幾件事,於是它把這些潛在需求也一起展開進去查。這是它在預判你的預判。這也是為什麼在 AI 搜尋時代,AISO 與AISO 戰略會把「預測讀者的下一個問題」當成內容設計的核心。
我把 Fan-out 想成一張網:你打的那個問題是一個結,展開出去的每一條線都是一個子查詢。網結得越密、越對齊讀者真正會問的東西,就越容易把你這一頁撈起來。
為什麼 AI 搜尋讓這個機制變得更重要
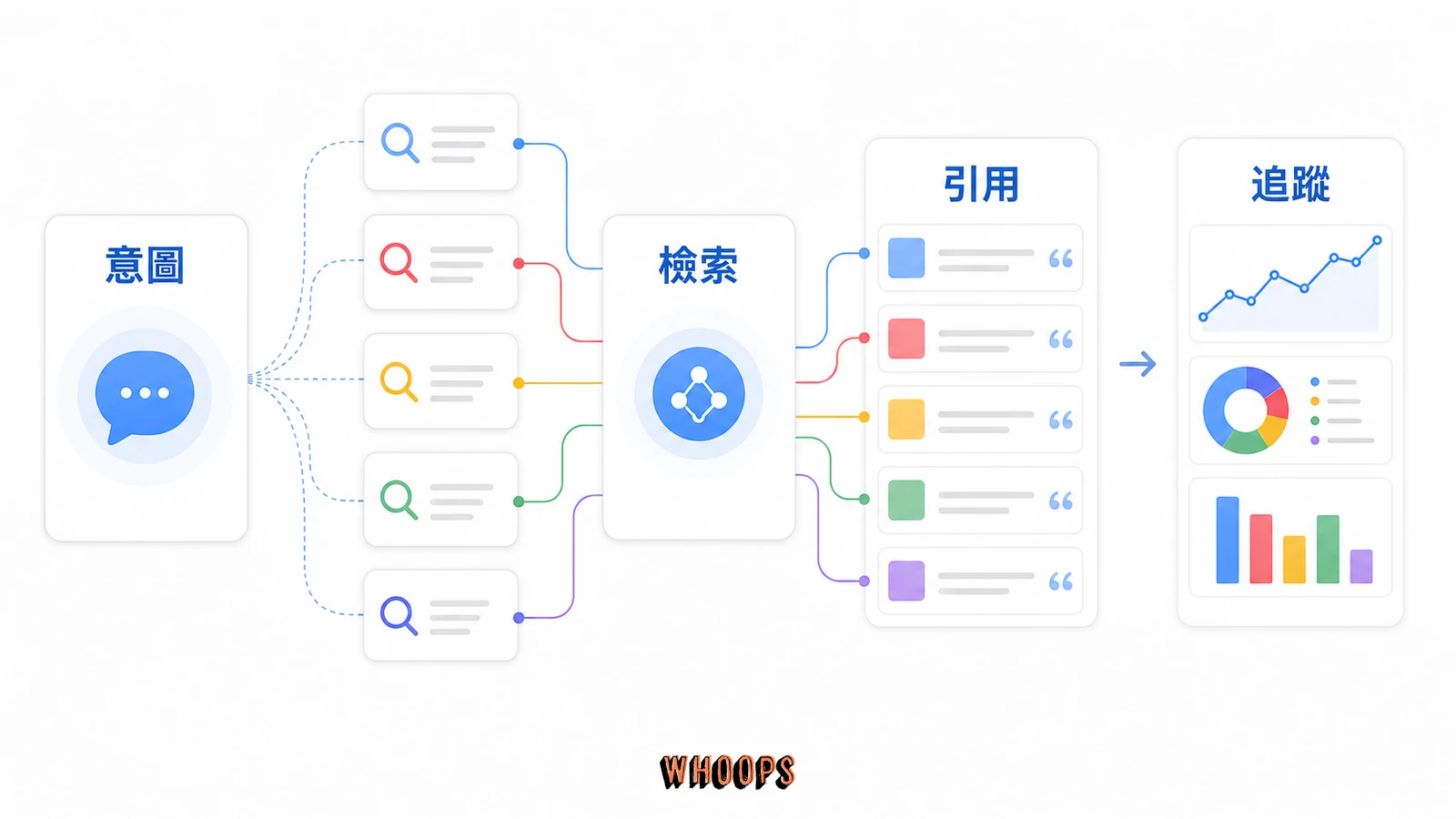
傳統的藍色連結時代,Fan-out 主要影響的是「哪些網頁有資格進入候選池」。到了生成式搜尋,它直接決定模型生成答案時會引用哪些來源、會回答哪些角度。當模型要先想清楚一個問題有哪些子面向、再逐一去找答案時,一篇內容如果只覆蓋單一角度,被引用的機率就低;反之,一篇把相關子問題都覆蓋到的內容,等於是整束子查詢的共同落點。
這也是為什麼很多人發現,在 AI Overviews 與 Google AI Mode 出現之後,過去那套「一個關鍵字配一篇文章」的打法越來越吃力。AI 搜尋需要的是能同時回答一束問題的頁面,而不是只對單一字面負責的頁面。如果對「AI 搜尋到底會不會吃掉 SEO 流量」還有疑慮,可以讀一下AI 搜尋 SEO 迷思破解;想理解 AI 搜尋怎麼改變自然排名的分布,則可以從結果頁結構的變化看起。
Fan-out 時代,關鍵字邏輯要怎麼跟著改
既然系統會自動展開查詢,是不是代表什麼都不用做、隨便寫就好?當然不是。系統變聰明,對內容的要求反而更高,因為它對「覆蓋度」與「重複度」都更敏感。繼續用舊方法操作,會踩到兩個明確的坑。
坑一:關鍵字吞噬
給你一個真實的失敗例子。兩年前有個開咖啡廳的客戶,為了搶排名,在部落格同時發了兩篇文章:一篇標題是「2026 台北咖啡廳推薦」,另一篇是「2026 台北咖啡店推薦」。內容幾乎一模一樣,只是把所有「咖啡廳」換成「咖啡店」。他的算盤是兩個關鍵字都吃。結果兩篇都沒排上,還因為內容重複性太高被系統判定為低品質,整個網站的權重被往下拉。
在 Fan-out 眼裡,「咖啡廳」與「咖啡店」是同一件事,本來就會被展開成同一束子查詢。你硬拆成兩篇,等於要系統在兩份幾乎相同的內容之間二選一,結果常常是兩份都不選。這就是關鍵字吞噬的典型樣態。
坑二:覆蓋度太窄
另一個方向的反面。有些內容把一個關鍵字寫得很深,卻只圍繞這一個字面打轉,完全沒有提到讀者真正會追問的周邊問題。Fan-out 展開出去的子查詢在你這一頁找不到著陸點,系統自然不會把你當成這一束查詢的答案來源。深,不等於廣;而 Fan-out 要的是廣度對齊。一個常見的盲點是,作者以為把一個字寫到極致就是專業,卻忘了讀者在問這個字之前與之後,還會連帶問哪些事。那些連帶的問題,才是 Fan-out 真正展開的範圍。
順著 Fan-out 寫內容:主題叢集而不是關鍵字清單
如果只能給一個方向,我會說:忘掉關鍵字密度,開始想覆蓋率。你要做的不是為每個變體關鍵字各寫一篇,而是寫一篇夠權威的內容,把這個主題底下讀者真正會問的相關概念一次收攏進來。這正好就是主題叢集(Topic Cluster)的思路:一個核心主題,往外接一圈相關子題,讓整束被展開的子查詢都能在這張網裡找到落點。想把這個架構落地,可以參考On-Page SEO 主題群集策略與集群內容的實作方式。
具體可以走的操作順序
- 鎖定一個核心主題,例如「手沖咖啡」。
- 列出讀者在這個主題下真正會追問的子問題,而不是列變體關鍵字。器具、水溫、研磨度、悶蒸、淺焙與深焙的差異,這些才是會被 Fan-out 展開出去的方向。
- 在文章裡自然地把這些子問題各用一個小段落回答,不需要刻意堆疊,但每一段都要真的給出答案,不能只是點到為止。
- 查一次 Google Search Console 的成效報表,把你「根本沒寫在標題裡、卻帶來曝光」的字詞挑出來,那些往往就是系統幫你展開出去、你卻沒好好回答的子查詢,把它們自然補進對應段落。
當你的頁面同時出現「水溫」「悶蒸」「研磨度」這些概念,而且每一個都真的講清楚,系統會判斷這不是一篇在亂塞字的文章,而是一篇真的在覆蓋手沖咖啡這個主題的文章。這時候你不只是排在「手沖咖啡」前面,連「咖啡豆怎麼磨」「沖咖啡水溫多少」這類你沒刻意處理的長尾查詢,也會被這同一束展開帶到你這一頁。這就是 Fan-out 給的紅利。把這個邏輯放大到整站,就是長尾關鍵字變現的現代打法,也是提升自然流量最穩的一條路。
Fan-out 與「查詢擴充」這個詞的關係
這裡順帶把名詞釐清一下,因為兩個說法常被混用。「查詢擴充(Query Expansion)」是個比較老的總稱,指任何把原始查詢加上同義詞、相關詞的技術;「Query Fan-out」是 Google 在生成式搜尋脈絡下特別強調的展開方式,重點在「把一個問題拆成一束子問題、同時去查」。你可以把 Fan-out 想成查詢擴充在 AI 搜尋時代的升級版:一樣是展開,但展開得更結構化、更貼近讀者真正的追問路徑。這也是為什麼它在 AEO 與 GEO 的討論裡被反覆提起,而Google 演算法更新的軌跡,正好可以佐證這條從字面走向意圖的路線。
在 AI 答案裡被引用,跟 Fan-out 有什麼關係
被引用這件事,還牽涉到一個結構性問題:你的內容是不是好引用。Fan-out 決定的是「這一束子查詢會去找誰」,但最終被模型挑中、寫進答案裡的,往往是那種把一個子問題用清楚、獨立的一段話回答完的頁面。如果你的答案是散落在整篇文章裡、需要讀者自己拼湊,模型引用的難度就高。這也是為什麼把每個子問題各用一段完整回答,不只是為了覆蓋度,也是為了可引用性。
很多人問,要怎麼做才會被 AI 答案引擎優先引用。我的觀察是,被引用的前提之一,就是你這一頁要剛好是某一束被展開子查詢的最佳答案集合。模型在生成答案時,會把它展開的那幾個子問題各自去找來源;如果你的頁面只回答其中一個、回答得不夠完整,就很難被選中。換句話說,被引用這件事,在機制面上有一部分就是 Fan-out 的覆蓋度問題。要把這件事做到位,避免關鍵字堆砌的前提下把語意相關性經營起來、E-E-A-T的累積,以及讓機器能穩定讀懂你內容的技術 SEO基礎,三者缺一不可。若要進一步對齊 AI 引擎的抓取習慣,llms.txt 部署也是值得排進時程的一塊。
Fan-out 跟「搜尋意圖」是同一件事的兩面
把 Fan-out 講清楚之後,有一個關係值得點出來:它與搜尋意圖其實是一體兩面。系統展開子查詢的依據,正是它對「讀者打這串字時,心裡真正想要什麼」的判斷;而這個判斷,本質上就是搜尋意圖的建模。換句話說,你越能精準對齊意圖,就越能在 Fan-out 展開的那一束子查詢裡命中要害,這也是蜂鳥演算法把勝負從詞彙密度轉向答案完整度之後,一路延續下來的方向。
這也解釋了為什麼只看字面的內容策略會失效。一個查詢可能同時帶有資訊型、商業型、交易型多種意圖成分,系統會把這些成分各自展開成一條子查詢,再去匹配能回答它們的頁面。如果你的文章只回答其中一種意圖,等於自動放棄了其餘幾束被展開的子查詢。把意圖拆開來看、逐一覆蓋,才是跟著 Fan-out 走的正確姿勢。這也是為什麼單純衝停留時間或字數,對現代排名的幫助有限;真正決定你能不能接住整束子查詢的,是覆蓋度對不對得上意圖。
實務上我會做一個很簡單的練習:拿你鎖定的主題,逼自己寫出五到七個「讀者可能接著問的問題」,再回頭檢查文章裡是不是每一個都有被好好回答。寫不出來,代表你對這個主題的覆蓋面還不夠;寫得出來卻沒寫進文章,那就是你親手把一束子查詢讓給了別人。這個練習做完之後,你會發現一篇合格的文章,其實已經在無形中鋪好了一個微型主題叢集,讀者停留的時間變長、跳出率跟著下降,這些行為訊號再回頭強化你在該主題的權威性。
Fan-out 會不會讓「精準匹配」完全失效
這是初學者最常問的問題:既然系統會自動展開,那我還需要在意標題與正文裡有沒有關鍵字嗎?我的答案是:需要的,但角色變了。關鍵字不再是「唯一的入場券」,而是「告訴系統這一頁的主題座標」。標題裡有核心詞,能幫助系統更快定位你屬於哪一束子查詢;但光靠精準匹配,已經不足以讓你在那一束裡勝出,勝負判斷會回到覆蓋度、深度與網站整體的權威性,這也是Google 證實的排名因素裡反覆強調的幾條主線。
Google 自己在說明搜尋運作方式時,也把「理解查詢」擺在「比對網頁」之前,這背後對應的就是 Fan-out 這類前置擴充的動作。所以與其問「我還要不要寫關鍵字」,不如問「我這一頁夠不夠資格成為某一束子查詢的最佳答案」。前者是十年前的問題,後者才是現在的問題。
幾個我會直接做的檢查動作
把上面的方向落成可執行的步驟,我自己會固定做這幾件事。
- 回去翻表現平平的舊文,看它是不是過度專注在單一關鍵字上。把讀者真正會追問的周邊概念補進去,擴大它的覆蓋面。這也是SEO 文章寫作裡最容易被忽略的健檢動作。
- 把 Search Console 成效報表裡「沒寫在標題、卻帶來曝光」的字詞挑出來。這些字詞就是系統幫你展開、你卻沒認真接住的子查詢,把它們自然補進對應段落。
- 用口語的方式把一個概念講給別人聽。你會發現自己會自然冒出各種同義詞與相關情境,那正是系統最喜歡、也最像真人的覆蓋方式。
- 定期檢查站內有沒有兩篇內容在搶同一束子查詢。有的話就合併或重新分工,不要讓系統在你自己人之間做選擇;分流清楚後,也可以靠點閱率與叢集內容的結構去強化每一束子查詢的主指定頁。
我知道改掉「為關鍵字而寫」的習慣不容易,尤其是被關鍵字密度這個觀念薰陶了這麼多年。但從這幾年的實測來看,當你開始為「人真正會問的問題束」而寫,而不是為單一字面而寫,自然排名反而起得比較穩。Query Fan-out 不會消失,它只會展開得更細;與其跟它對抗,不如順著它的展開方向,把每一束子查詢都接住。