文章目錄
CLAUDE.md 是什麼?一句話定位與它解決的真問題
CLAUDE.md 是 Claude Code 每次啟動時自動載入的 Markdown 專案說明檔,讓 AI 帶著正確的背景知識上工,而不是每次都從零猜你的慣例與地雷。把它放在專案根目錄就生效,不需要任何設定、不需要指令、不需要外掛,Claude Code 一開工就會去讀它。如果你還沒把 Claude Code 裝起來,先把完整 Claude Code 教學看過一遍,因為裝好之後,下一步就是把 CLAUDE.md 寫對,這份檔案決定了 AI 從第一句話開始有多聰明。
它解決的真問題只有一個:沒有它,AI 像一個新來的同事對你的專案一無所知。每次開工你都得口頭解釋「我們用 ESM 不要混 CJS」「標題不能送 slug 到 API」「API 要帶 User-Agent」,解釋完它下一輪還是會踩同一顆雷,因為這些規則沒有寫進它的記憶。寫對一份 CLAUDE.md,等於幫 AI 建立一份永久上工手冊,它每一次對話都會帶著這份手冊進來,不用你再重複交代。這也是為什麼 Claude Code 跟一般的對話型 AI 工具體驗差這麼多,Claude Code 有持久記憶,而一般對話每次都是失憶狀態,每一次都要你重新教一遍。你可以把它想成幫新同事寫一份 onboarding 文件,差別在於這份文件 AI 每天都會重讀一次,不會忘。
TL;DR:CLAUDE.md 是 Claude Code 開機自動讀的專案設定檔,分四層疊加、建議壓在 150 行內,只寫「AI 不知道就會出事」的地雷級規則,用 Always 或 Never 開頭才會被穩定遵守,寫對一份等於把新人上工手冊永久固化。
跟 Claude 產品線裡的對話工具不同,CLAUDE.md 是 Claude Code CLI 專屬的記憶機制,副檔名固定、檔名固定、沒得客製化。它跟 Claude 桌面版共用同一套底層引擎,但檔案層級與載入行為是 CLI 才有的特性。換句話說,同一個專案、同一個模型,有沒有寫 CLAUDE.md,AI 的行為會差到像是兩個不同的助理。下面從四層結構講起,一路講到可直接複製的範本與維護流程,這套方法不只適用 Claude Code,你在 Claude 相關的任何工作流程裡都能借鏡「把規範寫成可執行指令」這個核心觀念。
四層結構一次搞懂:Managed、User、Project、Local 各放什麼
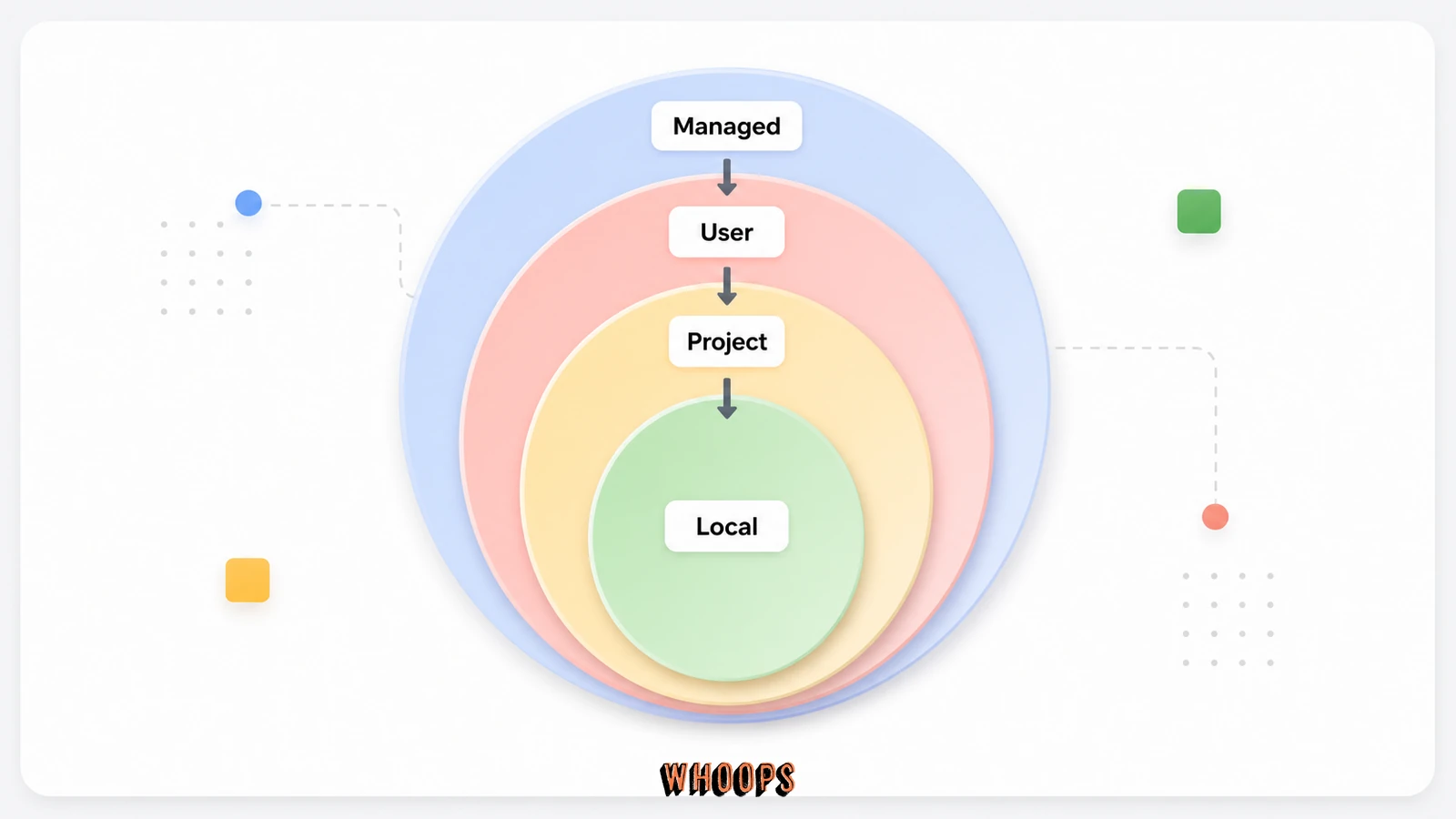
CLAUDE.md 不是單一檔案,而是四層疊加:Managed 企業強制鎖定、User 全域適用你所有專案、Project 這個專案全員共用、Local 只你自己且不進 git。範圍由大到小、後者補充前者,四層全部都會被載入,發生衝突時小範圍覆蓋大範圍。理解這個疊加邏輯,才知道每條規則該寫進哪一層,這也是新手最常搞混的地方。很多人以為 CLAUDE.md 就是一個檔案,寫錯位置、放錯層級,結果規則要嘛沒生效、要嘛污染到不該影響的專案。把四層想成四個同心圓,外圈是大範圍的共通規則,內圈是越來越個人化、越來越專案化的細節,全部疊在一起才是 AI 實際拿到的那份完整記憶。
第一層 Managed,是企業管理員設定,使用者無法覆寫,適合放合規與資安紅線,例如「Never commit secrets to version control」「Never disable security telemetry」。這一層是公司層級的硬規定,員工改不了,所以適合放絕對不能違反的東西,像是不能把金鑰寫進程式碼、不能關閉稽核日誌、不能繞過 code review 流程。如果你是個人開發者,這一層通常用不到,可以跳過,直接從第二層開始寫。第二層 User 全域,放在 ~/.claude/CLAUDE.md,裝的是你個人的通用偏好與跨專案編碼風格,像程式碼 review 心態、最小變更原則、不要引入不必要依賴這類你到哪個專案都成立的東西。這一層的好處是寫一次,所有專案都受益,等於你的個人工程紀律被永久固化,不管是哪個倉庫,Claude Code 都會帶著這套紀律上工。
第三層 Project,放在專案根目錄的 CLAUDE.md,是大家最常講、也最常寫錯的那一份。內容是技術棧、架構、規範、常用指令,還有最該投資的 Known Gotchas 高風險地雷段。這份會進版控、全員共用,所以寫在這裡的東西必須對整個團隊都成立,不能摻雜個人偏好。一個常見的錯誤是把「我習慣用 vim」「我喜歡某個 linter 設定」這類個人事寫進 Project 層,結果其他用不同編輯器、不同習慣的隊友就被綁住。第四層 Local 是 CLAUDE.local.md,裝本機路徑、個人除錯習慣、暫存筆記位置,務必寫進 .gitignore 不進版控,免得隊友 pull 下來看到一堆只存在你電腦上的路徑。這四層的設計哲學很清楚:越往底層越是個人化、越往頂層越是組織化,中間的 Project 層是團隊共識的載體。
這裡最常踩的雷是內容放錯層。個人路徑絕對不能進 Project 層,否則隊友 pull 之後看到的規則在他們機器上完全不成立,AI 還會傻傻去讀那些不存在的路徑報錯,這種問題很難察覺,因為你自己的機器上一切正常,只有隊友會踩到,而且他們通常不會立刻反應是 CLAUDE.md 的問題。企業資安紅線也絕對不能只靠 User 層自律,因為使用者可以自己改自己的全域檔,等於沒有紅線,這也是為什麼 Managed 層的存在是必要的,它讓合規要求變成不可繞過的硬限制。判斷放哪層的標準很簡單,四選一:這條規則是「全公司不能違反」「我個人所有專案都這樣」「這個專案全員都要」「只有我自己要用」。把這四個問題問一遍,答案就是它該住的層。很多人把 CLAUDE.md 寫壞,根因都是沒想清楚這個分層,把所有東西倒進 Project 層一份檔案,結果個人偏好污染團隊、企業紅線又沒有強制力,兩頭不討好。
到底該寫什麼?一個判斷公式與六個必寫區塊
判斷公式只有一句:拿掉這條規則,AI 會不會犯錯?會就寫、不會就不寫,別把整份 README 複製貼進去。這句話聽起來像廢話,但我看過太多人把 CLAUDE.md 當成專案文件總整理,技術背景、公司沿革、API 設計理念、架構演進史全塞進去,結果 AI 讀完抓不到重點,真正該遵守的地雷反而被淹沒在長篇大論裡,遵守率反而比沒寫還差。判斷公式的核心精神,跟 技術 SEO 講的「只做會影響排名的事」是同一個邏輯,把資源投在真正會出事的地方。一個簡單的驗證方式:把你想寫的每條規則,套上「拿掉它,AI 會怎樣」這個問句,如果答案是「沒差,它本來就會做對」,那這條就是多餘的,果斷刪掉。
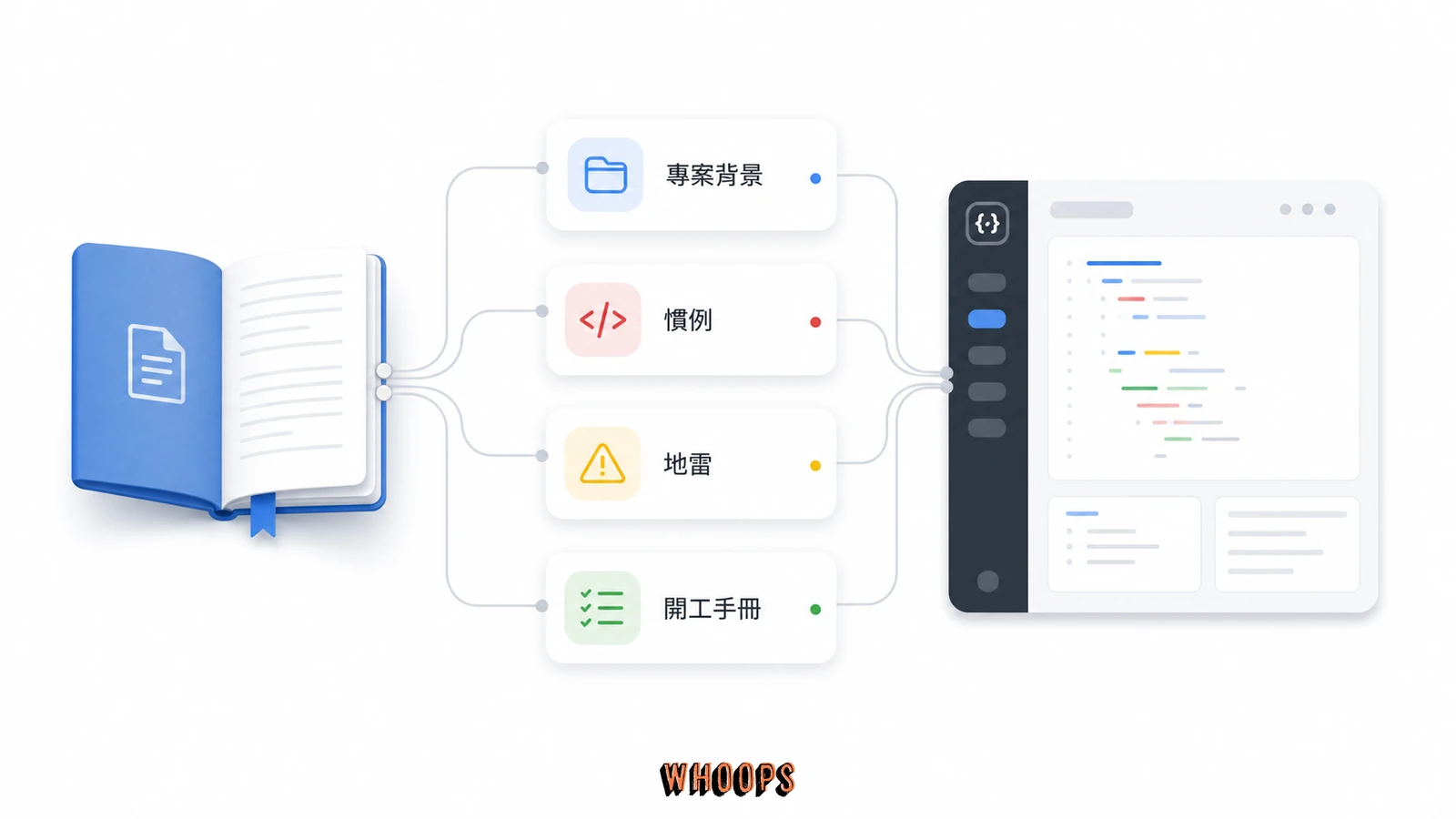
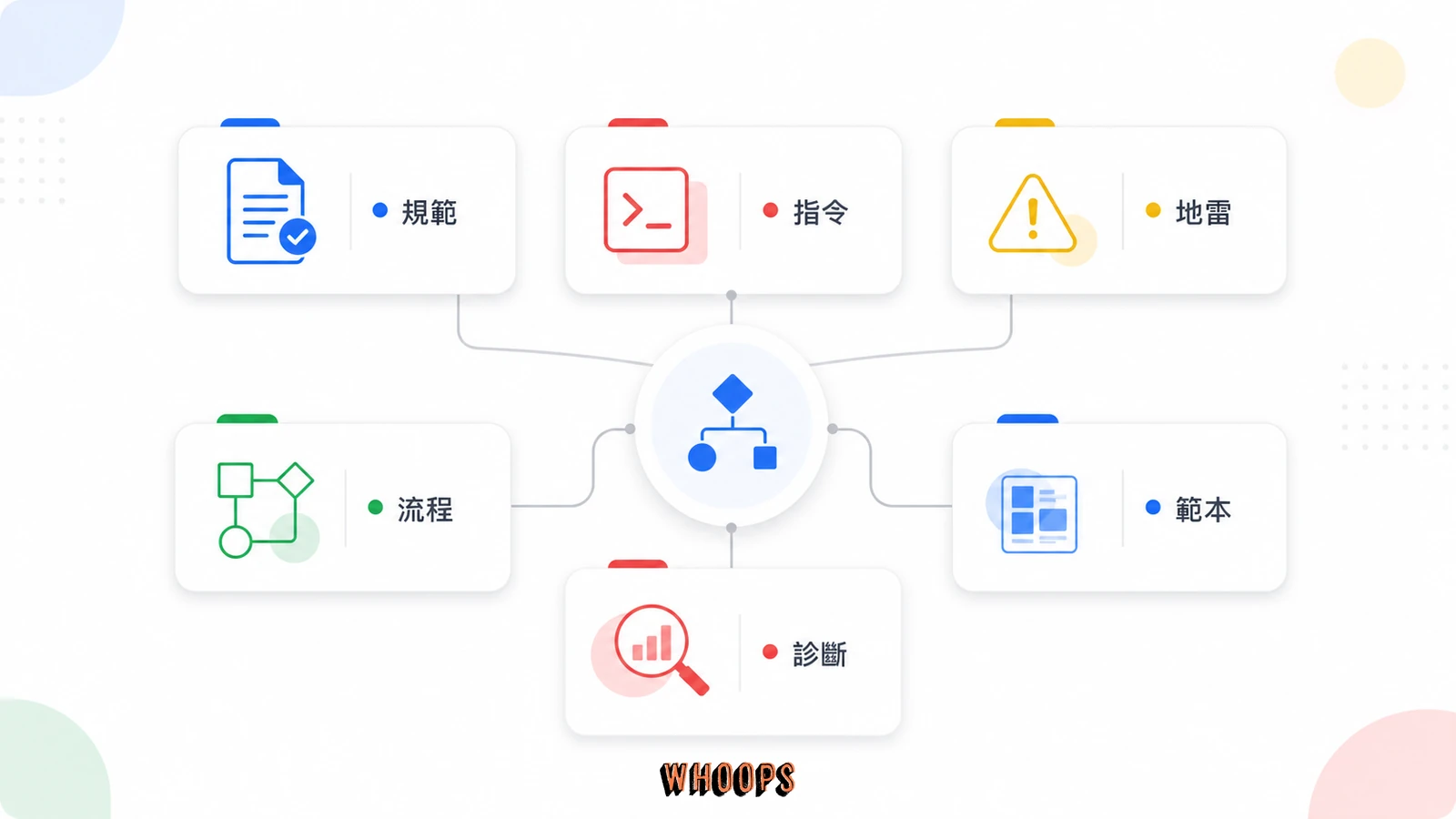
用這個公式過濾一遍,真正該寫的會收斂成六個區塊。第一是專案概覽,一行講清楚這是什麼、給誰用、解決什麼問題,讓 AI 第一時間建立正確心智模型,這比你想像的重要,因為 AI 對專案的理解錯了,後面所有產出都會跟著錯,例如它以為這是內部工具就會隨便寫,以為是對外產品就會更謹慎,定位決定它的謹慎程度。第二是技術棧與常用指令,AI 不會猜你要用 npm run dev 還是 pnpm dev,也不會知道測試是 npm test 還是 pytest,這些必須明寫,省下每次確認的往返,也避免 AI 自己選一個你沒裝的指令然後報錯給你看。
第三是架構與目錄結構,讓 AI 知道改某個功能要去哪個資料夾、動到哪些檔案會牽一髮動全身,這對大型專案特別關鍵,因為 AI 沒有你的心智地圖,它只看得到你這次開給它的檔案,架構段等於幫它建立全域視野。第四是規範與慣例,例如命名風格、錯誤處理模式、是否偏好函數式寫法、要不要加註解、commit message 格式。第五、也是最該投資的一段,是高風險地雷 Known Gotchas,寫那些 AI 不知道就會把生產環境搞爆的規則,像是「送 API 前要先 re-GET 確認」「這個欄位送錯會 clobber 其他資料」「這個設定檔改了要 purge 快取」「這個指令跑順序錯了會鎖死資料庫」。第六是常用工具呼叫方式,例如部署腳本、上傳腳本、資料庫遷移指令的正確參數與順序,這些 AI 用猜的很容易出事,因為它會用最常見的慣例去套,而你的專案慣例很可能跟主流不同。
每個區塊都有一行反例可以對照。「本專案使用 React」是常識不用寫;「本專案用 ESM,.mjs 用 import、.js 用 require,兩者不可混在同一檔案」才是該寫的地雷。「程式碼要簡潔」是廢話;「prefer smallest safe change, reuse existing helpers instead of adding new dependencies」才是可執行指令。把每條規則都拿這個標準檢驗一次,你的 CLAUDE.md 當場瘦身一半,而且更有效。地雷級規則的具體寫法,下一節直接用真實案例示範,比列一百條原則更有感。
真實 before/after:有寫規則 vs 沒寫,AI 行為差在哪
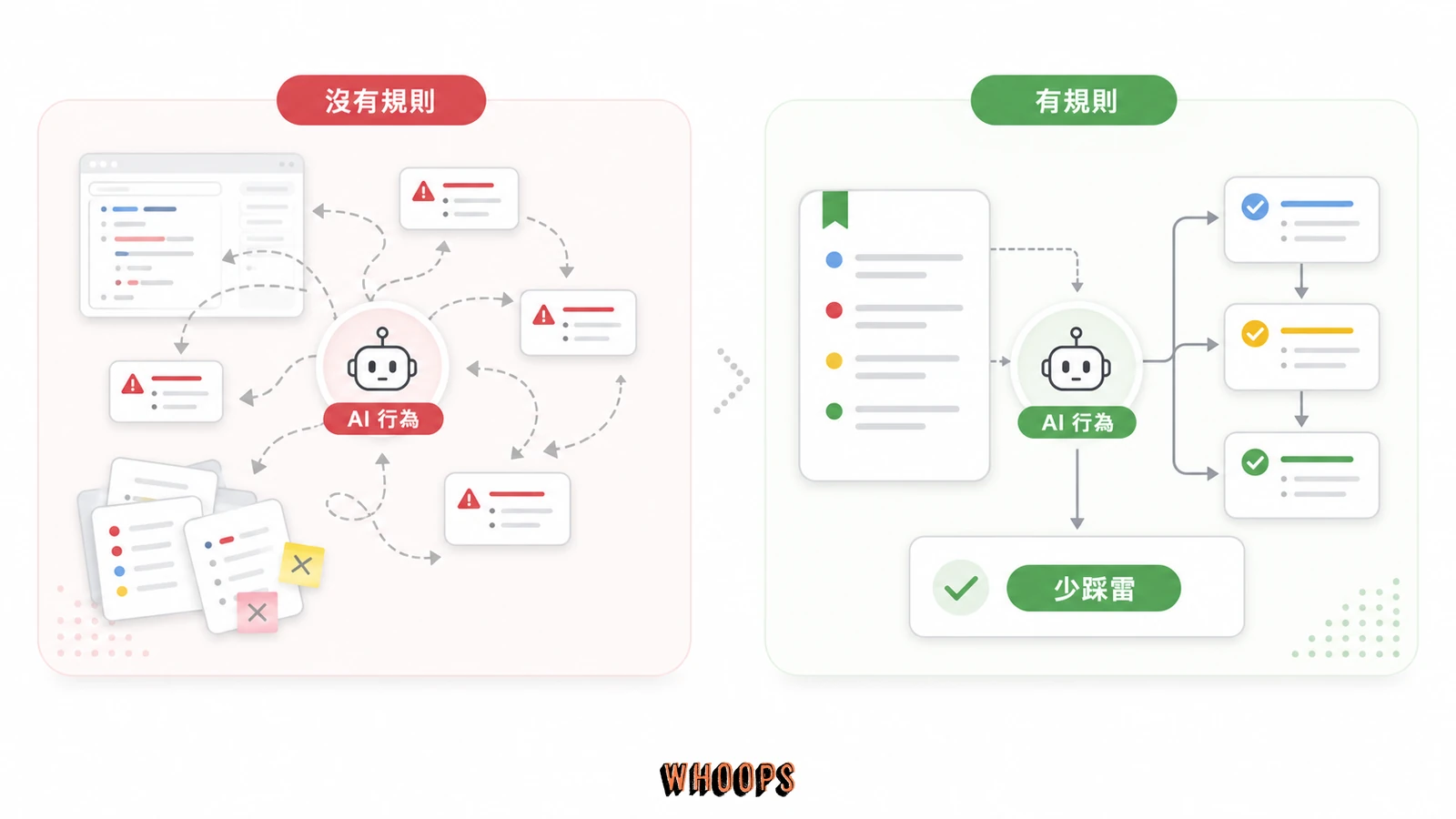
同一條規則寫進 CLAUDE.md 前後,AI 的產出會從「每次踩雷你要手動修」變成「自動避開」。這一節用我自己這個 codex 倉庫真實發生過的三條地雷規則示範,這些不是從官方文件抄來的理論,是踩過痛才寫進去的教訓。講了這麼多原則,不如看三個血淋林的對照,你會立刻理解為什麼寫規則的投資報酬率這麼高。
第一條,禁用中文破折號裡的雙連號符號。沒寫這條規則時,AI 寫中文長文會大量產出這個符號當連接號與轉折,我得手動全篇搜尋替換,一篇文章改下來幾十處,而且每次新生成都會再犯,等於永無止境的手工活。寫了之後,AI 產出零誤用,它自動改用括號、句號或其他合法寫法。這條規則的投資報酬率極高,一行字省下每篇文章十幾分鐘的手動清理,累積到幾百篇文章就是幾十小時。
第二條,不送 title: <slug> 到 WordPress REST API。沒寫時,AI 為了省事直接拿 URL slug 當標題送進 wp/v2/posts/{id},結果一次 clobber 掉 16 篇文章的標題與 Rank Math SEO 標題,復原花了一整個下午還有幾篇救不回完整狀態,這是那種會讓人冷汗直流的生產事故。寫了之後,AI 只送真實中文標題、同時送 rank_math_title,而且發布完會主動 re-GET 驗證 title.rendered 是 CJK 字元、不是 slug 字串,等於多了一道自動防線。這條規則背後牽涉的是 技術性設定的嚴謹度,一個欄位送錯就連帶影響 SEO 表現。
第三條,WordPress REST API 必帶 User-Agent header。沒寫時,API 回 403,我一度以為是應用程式密碼權限問題、還是 IP 被擋,繞了一大圈才發現純粹是缺一個 header,這種誤判會讓你浪費好幾個小時查錯方向,因為 403 直覺上就是權限問題,很少有人會聯想到是 header 缺失。寫了之後,AI 每次 GET 或 PUT 都自動補上 User-Agent,再也沒出現 403。這條規則還帶出一個更大的教訓:很多 API 錯誤訊息會誤導你,403 不一定是權限、500 不一定是伺服器壞掉,真正的根因常常藏在你看不到的細節裡,把這類經驗寫進地雷段,AI 才不會重蹈你查錯方向的覆轍。
把這三條放一起看,會發現一個共同結構:每一條都是「觸發條件+禁止或必做動作+正確做法」三段式,而且都用 Always 或 Never 開頭。這不是巧合,是寫法決定了遵守率。散文式的「記得注意一下標題格式」「API 呼叫時留意一下 header」,AI 幾乎不會當一回事;寫成「Never send title as slug, always send real title and re-GET verify」「Always include User-Agent header on every WP REST request」,AI 就會穩定遵守。原因在於指令式語言讓 AI 能直接對應到動作,而散文需要它自己推斷你到底要什麼,推斷就會出錯。這也是為什麼 Claude Code 的記憶檔要當程式碼來寫,而不是當文章來寫,每一條規則都該像一行可執行的指令。
可直接複製的 CLAUDE.md 範本:四層各一份加極簡版
以下四份範本可直接複製貼上對應路徑:User 全域、Project 專案、Local 個人,外加一份 35 行極簡專案版給不想寫長的人。每份都標了複製後要改哪幾格,別原封照抄,因為你的專案技術棧與地雷跟我不會一樣。範本是骨架,真正讓它有效的是你把自己踩過的雷填進去。
User 全域範本,放在 ~/.claude/CLAUDE.md,內容是個人編碼原則與 review 心態,這些是你到哪個專案都成立的通用紀律:
# 全域原則 - Read before editing. 永遠先讀相關檔案再改。 - Prefer smallest safe change that solves the actual problem. - Reuse existing helpers, never introduce new dependencies without reason. - Never fabricate test results, file contents, or API behavior. - Review mindset: assume work will be inspected line by line. - Preserve existing architecture, style, and naming conventions.
Project 範本,放在專案根目錄 CLAUDE.md,內容是完整六區塊,重點是開頭的 Quick Reference 高風險規則,這是全篇注意力最高的位置:
# {專案名}
## Quick Reference(最高風險,放最前)
- Never send title:slug to WP API, only real titles + re-GET verify.
- Always send User-Agent header on WP REST, or 403.
- Never commit secrets; .env is local-only.
## Overview
{一句話定位 + 目標讀者}
## Tech Stack & Commands
- 語言、框架、建置指令、測試指令、部署指令
## Architecture & Directory Structure
{目錄樹 + 各資料夾職責 + 牽一髮動全身的檔案}
## Conventions
{命名、風格、錯誤處理模式}
## Known Gotchas
{踩過才寫的地雷,每條配 before/after 行為差異}
Local 範本,放在 CLAUDE.local.md,記得加進 .gitignore,內容是本機專屬的東西:
# 本機專屬
- 本機測試網址:http://localhost:8080
- 我的除錯捷徑:npm run debug:watch
- 暫存筆記放 ~/notes/{project}/,勿進版控
35 行極簡版給新專案快速起步,只留專案概覽、技術棧、三條地雷、常用指令,其他等真的踩到雷再補。這個版本的好處是門檻低,先有再求好,比一份空白檔案強十倍。很多人卡在「不知道寫什麼」就一直不開工,結果 AI 從頭到尾都在裸奔,踩的雷累積成一堆手動修正工時;與其完美主義,不如先丟一份極簡版進去,邊用邊補,CLAUDE.md 是活的文件不是一次定稿的交付物。你可以想成,這份檔案會跟著你的 Claude Code 工作流一起演化,今天寫的 35 行,半年後可能長成 150 行的完整版,每一條規則背後都有一個真實踩過的雷當依據,這才是最可靠的累積方式。
CLAUDE.md 怎麼寫才有效?五個撰寫原則與三個常見無效寫法
有效的 CLAUDE.md 遵守五個原則:精簡、具體可執行、放地雷不放常識、用指令語氣、定期更新。最常見的無效寫法只有一種,就是把它當 README 寫。很多人以為寫得越完整越好,其實剛好相反,寫太多 AI 反而抓不到重點,地雷被淹沒在常識海裡。攤開來說,寫 CLAUDE.md 考驗的不是文筆,是判斷力,你能不能分辨哪些是 AI 本來就會的、哪些是它一定會踩的雷。判斷力來自實戰經驗,這也是為什麼資深開發者寫出來的 CLAUDE.md 比新手有效,不是因為文筆好,而是因為踩過的雷多,知道哪些規則真正值得寫進去。新手不必氣餒,從極簡版開始、邊踩雷邊補,半年後你的 CLAUDE.md 也會變得很有殺傷力。
原則一精簡優先,建議壓在 150 行以內,超過這個數字 AI 開始遺漏後半段內容,下一節會講背後的 context 成本理由。精簡不是少寫,是只寫有用的,兩者差很多,少寫是漏掉該寫的,精簡是砍掉不該寫的。原則二具體勝過抽象,「用簡單程式碼」這種寫法完全無效,AI 不知道你定的簡單是什麼標準;「prefer smallest safe change, reuse existing helpers」才有可執行性,AI 知道該怎麼對應到實際行為。你可以這樣測試一條規則夠不夠具體:把這條規則拿給一個不懂你專案的人看,他能不能照著做?不能的話,就是太抽象。抽象的形容詞是 CLAUDE.md 的毒藥,具體的動作描述才是解藥。
原則三放地雷不放常識,AI 本來就懂的東西不用寫,例如「JavaScript 是弱型別語言」這種常識寫了也是浪費 context,只寫它不知道會出事的。原則四用指令語氣,Always、Never、Prefer 開頭的規則,遵守率明顯高於散文描述,這在前面三條 before/after 案例已經驗證過,同樣的意思寫成「記得別用某符號」跟寫成「Never use 該符號」,後者效果天差地遠。原則五定期更新,地雷會演化,過時的規則比沒有規則更危險,因為它會誤導 AI 做出錯誤行為還自以為合規。
三個最常見的無效寫法要特別避開。第一是當 README 抄,把架構設計理念、技術選型理由、歷史演進全塞進去,AI 讀完只記得背景故事不記得地雷。第二是規則互相矛盾,例如同時寫「always add comments to every function」又寫「minimize diff and avoid noise」,AI 只好猜你要哪個,結果兩邊都不滿意。第三是寫成願景宣言,「我們重視程式碼品質」「追求卓越」這種句子對 AI 沒有任何行為指引,刪掉就好,留著只是佔 context。老實說,把這三種無效寫法都避開,你的 CLAUDE.md 已經比八成的人寫得好。
CLAUDE.md 多少行才適合?長度取捨與 context 成本
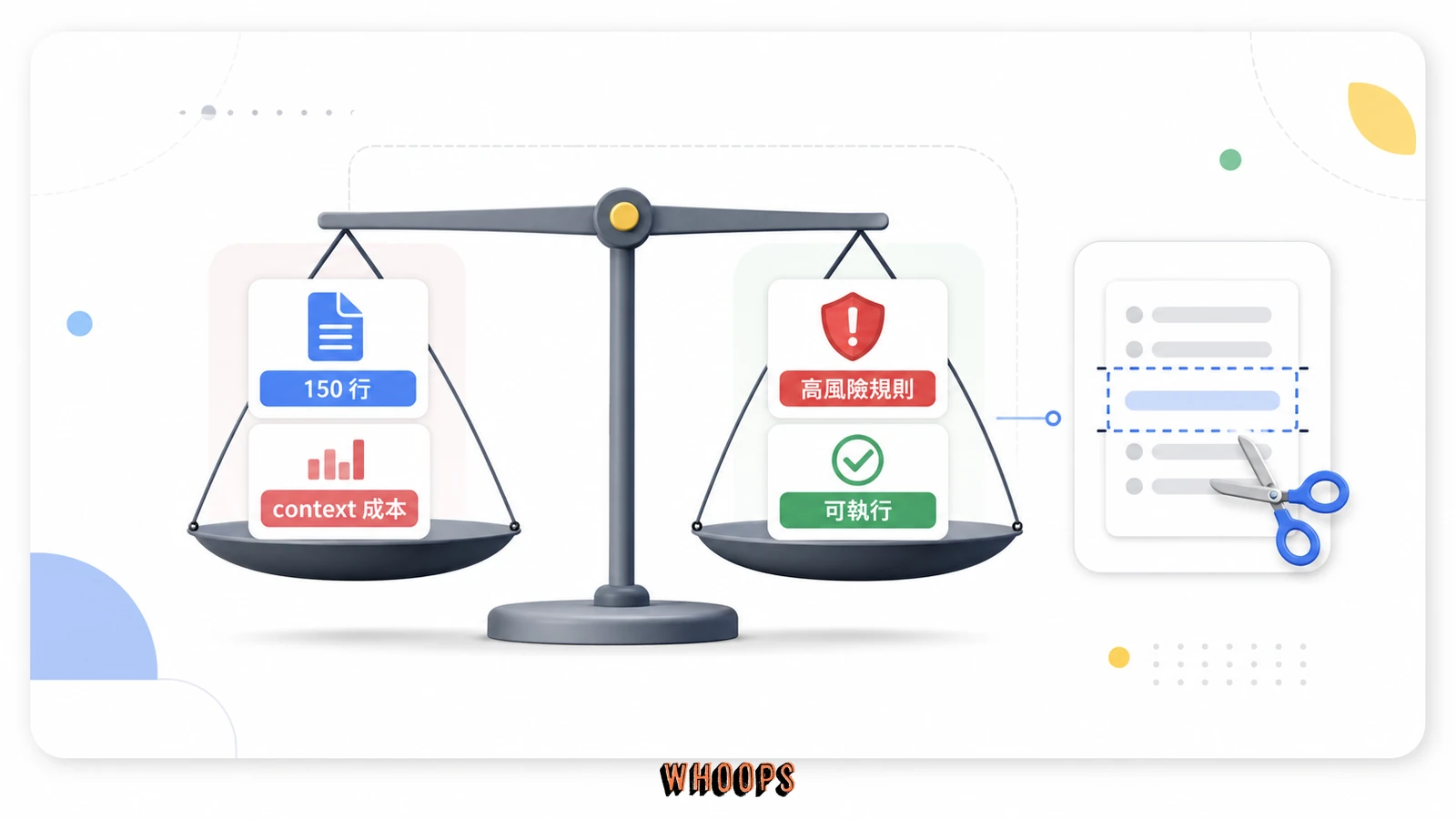
實務建議控制在 150 行以內、地雷段集中在開頭的 Quick Reference。理由很直接:CLAUDE.md 會佔用每一次對話的 context 空間,寫太長等於每次開工都先付一筆固定的 context 稅,還擠壓你真正任務能用的空間,同時讓 AI 抓不到重點。這不是感覺問題,是可量化的成本,每多一行就是每次對話多一份固定開銷,累積到幾百次對話就是顯著的浪費。更實際的影響是,當任務本身需要大量 context(例如讀一個大檔案、分析一段長程式碼),被 CLAUDE.md 吃掉的空間會直接壓縮你能餵給 AI 的任務內容,導致它看不全、判斷失準。所以控制長度不是潔癖,是效能最佳化。
為什麼抓在 150 行這個數字,是兼顧資訊密度與 AI 注意力的經驗值。觀察到的行為是,超過這個長度,AI 對檔案後半段的遵守率會明顯下降,你寫在結尾的地雷幾乎等於沒寫,這跟人類讀長文會越讀越漏抓不到重點是同一個機制。所以最該被遵守的高風險規則一定要放最前面,開頭是 AI 注意力最高的位置,這也是為什麼範本裡 Quick Reference 永遠在最頂端。直白地講,位置比數量重要,三條寫在開頭的地雷,效果勝過三十條寫在結尾的規則。如果你發現自己想寫的東西超過 150 行,先問自己:這些真的都是 AI 不知道就會出事的嗎?多半會發現有一半是常識或裝飾,砍掉就達標了。
降載的方法是拆層。把個人偏好移到 User 層、把專案細節移到對應子目錄的 CLAUDE.md,Claude Code 會依工作目錄載入對應層級,等於按需載入而不是一次全塞。比方說一個 monorepo 裡有前端、後端、基礎設施三個子專案,與其把三邊的地雷全塞進根目錄,不如各自在子目錄放一份 CLAUDE.md,當你在前端目錄工作時只載入前端相關規則,context 占用立刻減三分之二。什麼時候可以超過 150 行?大型 monorepo、多地雷專案這種情況可以放寬,但前提是搭配目錄結構分流,讓每個子目錄自己消化一部分地雷,而不是全部塞進根目錄那一份變成失控的長文。回顧一下,核心原則就是地雷放最前、個人移到全域、細節拆到子目錄,這三招組合起來,再大的專案都能把 CLAUDE.md 控制在有效範圍。
CLAUDE.md vs AGENTS.md:差在哪、團隊兩種 agent 並存怎麼辦
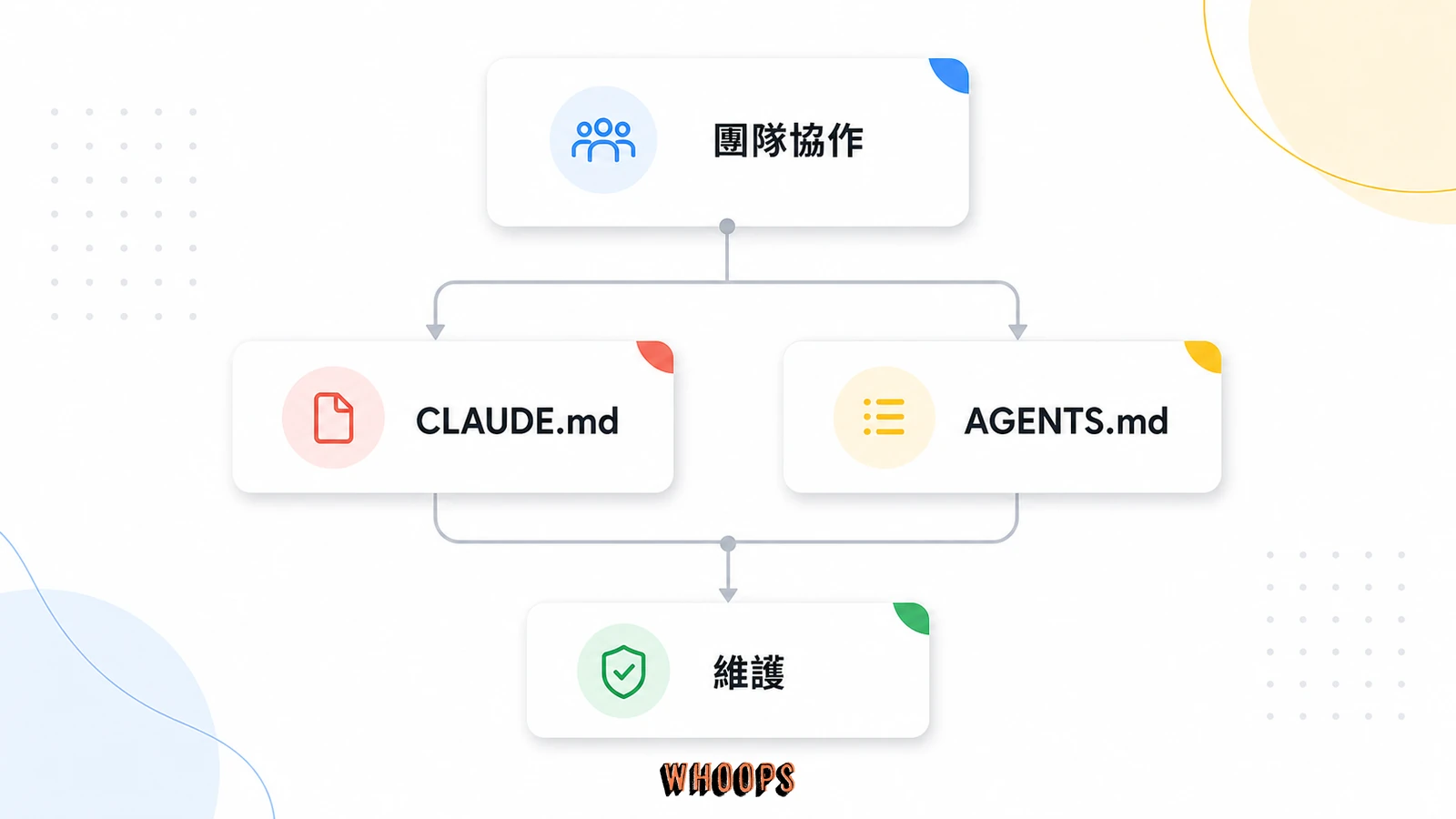
CLAUDE.md 給 Claude Code,AGENTS.md 給 OpenAI Codex,兩者語法與分層不同,不能互相取代。最常見的誤解是「反正都是 Markdown,寫一份兩邊通用就好」,實際混用的下場是其中一邊的 AI 讀到錯誤規範,行為對不上你的預期,而且除錯時還會誤以為是模型本身的問題,因為你會直覺怪罪 AI 讀不懂,而不會懷疑是設定檔格式不對。要理解兩個工具的根本差異,可以先看 OpenAI Codex 的定位與運作方式,再回頭比對 Claude Code 的設計,兩邊各自讀完,你會發現它們對「規範檔該長怎樣」的假設其實差很多。
本質差異在於,CLAUDE.md 是純 Markdown、彈性高、靠標題與條列組織,你愛怎麼排就怎麼排,只要 AI 讀得懂就行;AGENTS.md 偏結構化設定,欄位與覆蓋層級都跟 Claude 的四層不同,有比較固定的組織方式。覆蓋範圍也是,Claude 是 Managed、User、Project、Local 四層疊加,Codex 的設定層級與合併行為是另一套規則,兩邊的分層邏輯不能直接套用。這也是為什麼直接複製貼上會出問題,看起來一樣的規則,在兩套系統裡的實際作用可能完全不同,例如同一條「不要提交金鑰」的規則,在 Claude 寫在 User 層會跨所有專案生效,但在 Codex 可能需要寫在不同的設定位置才有一樣的效果。真要說的話,這兩份檔案服務的是兩個不同生態,把它們想成兩種不同框架的設定檔,而不是同一份文件的兩種格式,觀念就會清楚很多。
團隊同時用兩種 agent 時,建議走單一事實來源原則,避免兩份規範各自漂移。實務做法是以 CLAUDE.md 為主、用腳本或 CI 同步產出 AGENTS.md,兩邊有差異的段落明確標註,例如「Codex 不支援這條分層,改寫成全域規則」。這樣改一份、兩邊同步,不會出現改了 A 忘了改 B、規範漸行漸遠的情況。換個角度想,規範檔本身就是一種程式碼,單一事實來源、自動產出衍生版本,是已經被驗證過的工程紀律,套用到 AI agent 設定檔完全成立。如果團隊規模小、只用其中一種 agent,那就不用管這個問題,專心把那一份寫好就好,不要為了未來可能用到的另一種 agent 而提前增加維護負擔,YAGNI 原則在這裡一樣適用。如果你想看 Claude Code 與 Codex 從定位、效能到費用的完整對決,延伸閱讀〈Codex vs Claude Code 完整比較〉。
CLAUDE.md 怎麼維護與診斷:寫了沒效的五個原因
CLAUDE.md 寫了卻沒效,九成是下面五個原因之一:檔案沒被載入、規則太長被忽略、寫成 README 抓不到重點、規則互相矛盾、過時未更新。診斷的第一步永遠是先確認檔案到底有沒有被載入,因為前面四個原因再怎麼調都沒用,前提是檔案根本沒進到 AI 的視野。不過話說回來,很多人連這第一步都跳過,直接懷疑模型不夠聰明,其實問題出在自己的設定。
原因一檔案位置錯,沒放專案根目錄、檔名拼錯、放錯層,都會讓 Claude Code 讀不到。這是最常見也最容易被忽略的原因,因為你不會收到任何錯誤訊息,Claude Code 不會跳出來跟你說「我找不到 CLAUDE.md」,它只是靜默地用沒有記憶的狀態工作,你卻以為規則有生效。確認方法是用 /memory 指令,它會列出目前實際載入的所有 CLAUDE.md 內容,沒看到你的規則就是沒載到。原因二規則太長,超過 150 行 AI 開始忽略後半,解法是精簡或拆層。原因三寫成 README,AI 抓不到可執行指令,改用 Always 或 Never 語氣重寫,把散文改成指令。
原因四規則矛盾,兩條規則打架 AI 只好用猜的,審查時直接刪掉一條或合併成一條明確的。這種矛盾常常是無意間造成的,例如你三月寫了「always add type annotations」,六月又補了一條「minimize diff for hotfix」,遇到 hotfix 時 AI 就不知道該不該加型別標註。原因五過時,專案演化後舊規則反而誤導,例如改了框架但規則還寫舊框架的指令、改了部署流程但規則還寫舊腳本,這種隱形地雷最危險,因為它會讓 AI 自信地做錯事,你還以為它照規則來沒問題,其實規則本身已經是錯的。退一步看,CLAUDE.md 的維護成本其實不高,關鍵是建立固定節奏而不是想到才改,每月一次的 review 不到半小時,卻能避免規則腐化帶來的累積傷害。
維護流程建議這樣跑:每個月固定 review 一次,把過時的刪掉、把新踩到的雷補上;每次發生地雷事件,當下立刻補一條規則,趁記憶鮮明寫得最準,事後補通常會漏掉細節,因為你會忘記當時具體是哪個欄位、哪個參數出問題;用 git 追蹤 CLAUDE.md 的變更原因,commit message 寫清楚是哪個事件觸發的修正,這樣未來 review 時看得到每條規則的來龍去脈,也方便隊友理解為什麼有這條規則存在。把 CLAUDE.md 當程式碼一樣版本控,它才會越用越準、越用越貼近專案真實狀態,而不是一份越積越厚、沒人敢動的化石文件。這套維護紀律,跟你經營 技術 SEO 一樣,需要的是持續校準而不是一次到位,網站的技術債會累積,CLAUDE.md 的地雷清單也會累積,差別只在於你有沒有定期清。
寫好 CLAUDE.md 後,下一步是用 Plan Mode 與權限護欄鎖住 AI 行為(〈Claude Code 安全設定實戰〉),並評估自己的方案成本(〈Claude Code 費用與方案選擇〉)。
常見問題(FAQ)
CLAUDE.md 要寫什麼?
只寫「AI 不知道就會出事」的內容,收斂成六個區塊:專案概覽、技術棧與指令、架構與目錄、規範與慣例、高風險地雷、工具呼叫方式。判斷標準只有一句,拿掉這條規則 AI 會不會犯錯,會就寫、不會就別寫,更不要把整份 README 抄進去。地雷段是最該投資的一塊,因為它直接決定 AI 會不會把生產環境搞爆,這也是 Claude Code 用得好不好的分水嶺。新手最常犯的錯是花太多力氣寫概覽跟技術棧,卻在地雷段只寫兩三條敷衍的,本末倒置。
CLAUDE.md 有幾層?Managed、User、Project、Local 差在哪?
四層。Managed 是企業強制鎖定、使用者不能改;User 全域在 ~/.claude/CLAUDE.md,裝你個人到哪都用的偏好;Project 在專案根目錄,是全員共用的技術與地雷;Local 是 CLAUDE.local.md,只你自己、不進 git。範圍由大到小、後者補充前者,衝突時小範圍覆蓋大範圍。個人路徑千萬別進 Project 層,企業紅線也別只靠 User 自律。個人開發者通常只會用到 User 跟 Project 兩層,加上偶爾的 Local,Managed 層是團隊與企業才需要關心的。
CLAUDE.md 多少行才適合?可以超過 150 行嗎?
建議 150 行以內,因為它會佔用每次對話的 context。超過這個長度,AI 對後半段遵守率下降,地雷放結尾等於沒寫。大型 monorepo 或多地雷專案可以放寬,但前提是拆到子目錄分流,讓每個子目錄自己消化一部分地雷,而不是全塞根目錄那一份。關鍵判斷是資訊密度,不是總行數,同樣 150 行,全塞地雷跟摻一半常識,效果天差地遠。真的不確定,就從 50 行開始,用一陣子看 AI 哪裡常出錯,再針對性地補,比一開始就想寫滿 150 行更務實。
CLAUDE.md 跟 AGENTS.md 差在哪?團隊兩個都用怎麼辦?
CLAUDE.md 給 Claude Code,AGENTS.md 給 OpenAI Codex,語法與分層不同,不能互相取代。團隊兩個都用時,以 CLAUDE.md 為單一事實來源,用腳本同步產出 AGENTS.md,差異段標註清楚,避免兩份規範各自漂移到對不上。絕對不要手動維護兩份,一定會漸行漸遠。
CLAUDE.md 寫了 AI 還是不遵守怎麼辦?
依序排查五個原因:檔案沒被載入(用 /memory 確認)、規則太長被忽略、寫成 README 抓不到重點、規則互相矛盾、過時未更新。八成是前三個,尤其要檢查規則是不是用 Always 或 Never 開頭,散文式描述的遵守率明顯較低。先確認有沒有載入,再檢查寫法,接著才考慮內容本身。如果五個都排除了還是不遵守,那通常代表這條規則本身寫得不夠具體,AI 理解不了你要的精確動作,把它改寫成帶觸發條件與明確動作的三段式指令再試一次。
CLAUDE.local.md 是什麼?要進 git 嗎?
CLAUDE.local.md 是第四層 Local,裝本機路徑、個人除錯習慣、暫存筆記這類只屬於你的東西。絕對不要進 git,要寫進 .gitignore,否則隊友 pull 下來會看到一堆只存在你電腦的路徑,也會把個人偏好污染到團隊規範,造成規則來源混亂。它的存在就是為了讓個人流東西有地方放,又不影響其他人,概念上跟 .env.local 之類的本機設定檔一樣,是個人化的、不入版控的、只對你自己生效的一層。
怎麼確認 CLAUDE.md 有被 Claude Code 載入?
在對話裡輸入 /memory 指令,它會列出目前實際載入的所有層級 CLAUDE.md 內容。如果看不到你寫的規則,代表檔案位置錯、檔名拼錯、或放錯層,回頭檢查是不是放在專案根目錄、檔名是不是正好 CLAUDE.md 這幾個字、有沒有多打空格或副檔名。這是診斷沒效問題的第一步,確認載入之後才談得上調內容。養成習慣,每次新增或大改 CLAUDE.md 之後跑一次 /memory 確認,省得事後除錯半天才發現規則根本沒進 AI 的視野。
說到底,CLAUDE.md 不是文件,是給 AI 的行為指令。寫對一份,等於把新同事的上工手冊永久固化,AI 每次都帶著它進對話,不再踩同樣的雷,你也不用每次開工都重新教一遍。關鍵就三件事:只寫地雷級規則、用 Always 或 Never 開頭、壓在 150 行內。這套方法落地,建議先從一份 35 行極簡版開始,踩到雷再補,比追求一次寫完美更實際,也更容易養成維護習慣。記住,CLAUDE.md 的價值不在於一次寫得多漂亮,而在於它能不能持續攔截 AI 會犯的錯,這是一場長期賽,不是一次性交付。
想從安裝到進階用法一次看懂 Claude Code,回到完整 Claude Code 教學主篇;如果你關心的是 AI 搜尋時代的內容曝光,AEO 是什麼、技術 SEO 基礎與llms.txt 指南是延伸方向,把 AI 工具鏈跟搜尋曝光串起來看會更有全局感;想理解 AI 怎麼讀懂網站之間的關聯,內部連結是什麼能補上這塊,因為 AI 引擎跟傳統搜尋引擎一樣會爬內部連結來理解站點結構;而要把 Claude 生態看全,Claude 產品線總覽、桌面版介紹與 Codex 對照值得一併讀,搞清楚每個工具的定位,才知道 CLAUDE.md 在整個工作流裡扮演什麼角色。把這些讀完,你對 AI coding 的設定與協作會有完整的地圖,不會再只盯著單一檔案見樹不見林。