
「已建立索引,但未包含內容」的意思是 Google 已經把這個網址收進索引庫,但在抓取時拿不到任何實際內容,通常因為 robots.txt 明確封鎖,或伺服器、CDN、WAF 把 Googlebot 的 IP 直接擋下。根據 Google 官方對 Google 搜尋運作 的說明,索引建立分成檢索、處理、收錄三階段,只要抓取階段拿不到內容,這個頁面在搜尋結果裡就形同空殼。修復方向不是改 JavaScript 或補內容,而是放行 Google 的 IP,做法請見下方步驟。
本文重點先看
• 核心成因:這個狀態八成不是你的內容或 JavaScript 出問題,而是 Googlebot 在抓取階段被 robots.txt、Cloudflare WAF 或伺服器防火牆擋下,屬於基礎設施層。
• 為什麼本地測正常:現代防火牆認 IP 不認 User-Agent,你的瀏覽器、curl、第三方工具用的都是一般 IP,所以測不出來,只有 GSC 的「測試公開網址」能重現。
• 修復三步:先用 GSC 網址檢查確認現況,再查 robots.txt 與 CDN 設定,接著看伺服器日誌找 Googlebot 的真實回應碼。
• 預期時間:修完觀察 7 到 28 天,排名才會慢慢回來,這是實務區間,不是 Google 的官方保證。
TL;DR:「已建立索引但未包含內容」九成是 Googlebot 被 Cloudflare 或伺服器防火牆在 IP 層擋下,不是 JavaScript 或內容問題。先用 GSC 測試公開網址抓證據,再放行 Verified Googlebot,修完重交 sitemap,觀察 7 到 28 天。
文章目錄
先把結論講清楚:「已建立索引但未包含內容」是什麼意思?
它的意思是 Google 已經把這個網址放進索引資料庫,但在抓取時拿不到任何實際內容,所以這個頁面在搜尋結果裡形同空殼。用白話說,就像米其林評審把你的店列進名單了,但走到門口被警衛擋住,或店裡空無一物,評審只能記下「這家店存在」,寫不出任何評價。這是急重症,不處理的頁面到頭來會被整個踢出索引,流量直接歸零。這跟 Caffeine 索引系統 偶發的烏龍不同,後者是 Google 自己的問題會自行修復,這個則是你網站的設定出了狀況。
這裡要先拆開兩個常被混在一起講的狀態。第一個是「Indexed, though blocked by robots.txt」,意思是你的 robots.txt 明確寫了 Disallow,Google 抓不到但還是記下了網址。第二個才是「Indexed without content」,抓是抓到了,但內容是空的、薄的,或被判定為 soft 404。兩者成因不同,修復方向也不同,很多被忽略的技術 SEO 盲點 就出在這裡,把不同狀態當成同一件事來修。
這個狀態會出現在 GSC(Google Search Console)的哪裡?路徑是「網頁索引建立報告」→「為什麼網頁未建立索引」之外的另一區「例外」→「已建立索引,但未包含內容」。你會在這裡看到受影響的網址清單,數量可能從一頁到整站都有。如果你是第一次看到這個紅字,先別慌,它代表的是「有問題但還能救」,比「已從索引移除」嚴重程度低一階,但拖久了會往最壞的方向走。對 GSC 報告整體不熟的話,先把 GSC 警告怎麼處理 看一遍建立概念。
被收進索引卻沒內容,等於沒有價值
Google 只知道這個 URL 存在,讀不到標題、描述、正文,自然也沒辦法把它排進任何有意義的位置。換句話說,這個頁面在搜尋結果裡幾乎等同不存在。這也是為什麼這個錯誤要優先處理,它不像排名下滑那樣還有個位置,而是直接從搜尋結果消失。如果你的重要流量頁落在這裡,影響會立刻反映在 自然流量 的斷崖式下跌上。
為什麼 Googlebot 被封鎖,頁面還是會被建立索引?
因為 robots.txt 的 Disallow 只禁止「抓取內容」,並不禁止「建立索引」。只要 Google 從站內連結、外部連結或 sitemap 得知這個網址存在,它還是會把 URL 放進索引,只是裡面什麼都沒有。這是 SEO 最普遍的誤解之一:「禁止抓取不等於禁止索引」,搞懂 Google 搜尋運作方式 的三階段就會更清楚。
把三種封鎖機制的差別分清楚,你才不會修錯方向。Disallow 寫在 robots.txt,作用是禁止 Googlebot 抓取頁面內容,但 URL 仍可能被索引;noindex 是 meta 標籤或 HTTP 標頭,作用是明確告訴 Google「不要把這頁放進索引」,前提是 Google 要抓得到這頁才看得到這個指令;X-Robots-Tag 是伺服器回應標頭層級的 noindex,效果一樣但放在 HTTP 層。這三者的優先級和搭配方式,跟 內部連結 的規劃一樣,錯一個設定就會連帶出問題。
這裡要小心一個反向陷阱。有些站長想「先讓頁面被索引,但又怕被爬太多」,於是一邊用 robots.txt 擋,一邊期待 Google 收錄,結果正好製造出「已建立索引但未包含內容」這個錯誤。因為 Google 看不到頁面內容,也就看不到你可能放在裡面的 noindex,等於兩頭落空。
正確做法:要索引就放行,不要索引就 noindex
原則很簡單。要索引的頁面,就放行抓取,不要用 robots.txt 擋;不要索引的頁面,就用 noindex,而且不能同時用 robots.txt 封鎖,否則 Google 永遠看不到那個 noindex 指令。這聽起來像廢話,但實務上踩到的人多到嚇人,尤其是剛接手別人網站的時候,前手留下的設定往往就是這種自相矛盾。
別再怪 JavaScript 了:Google 點出真正盲點
多數人看到這個錯誤,第一反應是「我的 JavaScript 渲染是不是失敗了?」直覺怪前端。但 Google 的搜尋倡導者 John Mueller 曾公開說明,這類問題通常是伺服器或 CDN 正在封鎖 Googlebot,是基礎設施層級的問題,跟你網頁裡的內容或 JavaScript 沒有直接關係。我在這裡不直引他的原話,因為這段陳述散見於多場 Webmaster Central hangout 與 Reddit 回覆,但大意是穩定的:先查基礎設施,再查內容。
這個誤判會浪費大量時間。團隊花好幾天檢查 React、Vue、SSR 設定,跑 Google 抓取 JavaScript 連結 的各種測試,結果真正問題出在 Cloudflare 一個 WAF 規則。應用層(前端渲染)和基礎設施層(防火牆、WAF、CDN)是兩個完全不同的戰場,先確定戰場在哪,才不會白忙。這也是為什麼 John Mueller 強調網站越簡單越好懂,排查時才能快速定位問題層級。
這裡要誠實承認一個限制。JavaScript 渲染失敗「確實」也會造成無內容的結果,但它通常會伴隨其他症狀,例如 Rich Results Test 顯示空白、或 GSC 的「測試公開網址」回傳的 HTML 比瀏覽器看到的少一大截。要用 技術 SEO 的 URL 檢查工具把兩者區分開,不能一概而論。如果你測出來抓到的 HTML 完全是空的,連 doctype 都沒有,那幾乎可以排除 JavaScript,問題往上推到伺服器或 CDN。
為什麼本地測試永遠測不出來?IP 等級封鎖的原理
因為現代防火牆與 CDN 是「認 IP 不認 User-Agent」。你的瀏覽器、curl 假裝成 Googlebot、第三方檢測工具,用的都是一般 IP,所以全部放行;但真正的 Googlebot 帶著 Google 專屬 IP 來訪時,被誤判成高頻請求或可疑流量就直接擋下。你在本地端怎麼測都測不出來,因為你不是用 Google 的 IP。
這句「認 IP 不認 UA」要反覆強調,因為它推翻了多數人「改 User-Agent 就能模擬 Googlebot」的錯覺。你有用過那種把 User-Agent 改成 Googlebot 字串的線上檢測工具嗎?測試還是會過,對吧。為什麼?因為你的請求還是從一般 IP 發出,防火牆根本沒把你當 Googlebot,自然也沒擋你。真正能準確重現問題的,只有 GSC 內建的「測試公開網址」,因為它是真的從 Google 基礎設施發出請求。
WAF 的 IP 信譽評分怎麼運作
雲端防火牆背後通常有一套 IP 信譽評分機制。Google 的 IP 段因為請求量大,可能被某些評分系統標記為高頻來源,一旦超過限流閾值就觸發封鎖。這種封鎖是動態的,有時候通、有時候擋,讓排查更棘手,因為你 GSC 測一次成功不代表下次也成功。想知道哪些設定會踩到,可以對照 網站程式碼最佳化 與伺服器層的檢查清單,或從 行動優先索引延遲 的排查邏輯借鏡。
這也解釋了為什麼這個錯誤常常是「某天突然出現」。你的網站跑了半年都沒事,某天 CDN 業者推了一條新的預設 WAF 規則,或你調了 Bot Fight Mode,Googlebot 就被無聲擋下,而你一無所知,直到打開 GSC 才看到紅字。這種沉默的故障是最危險的,因為沒有任何監控會主動通知你。
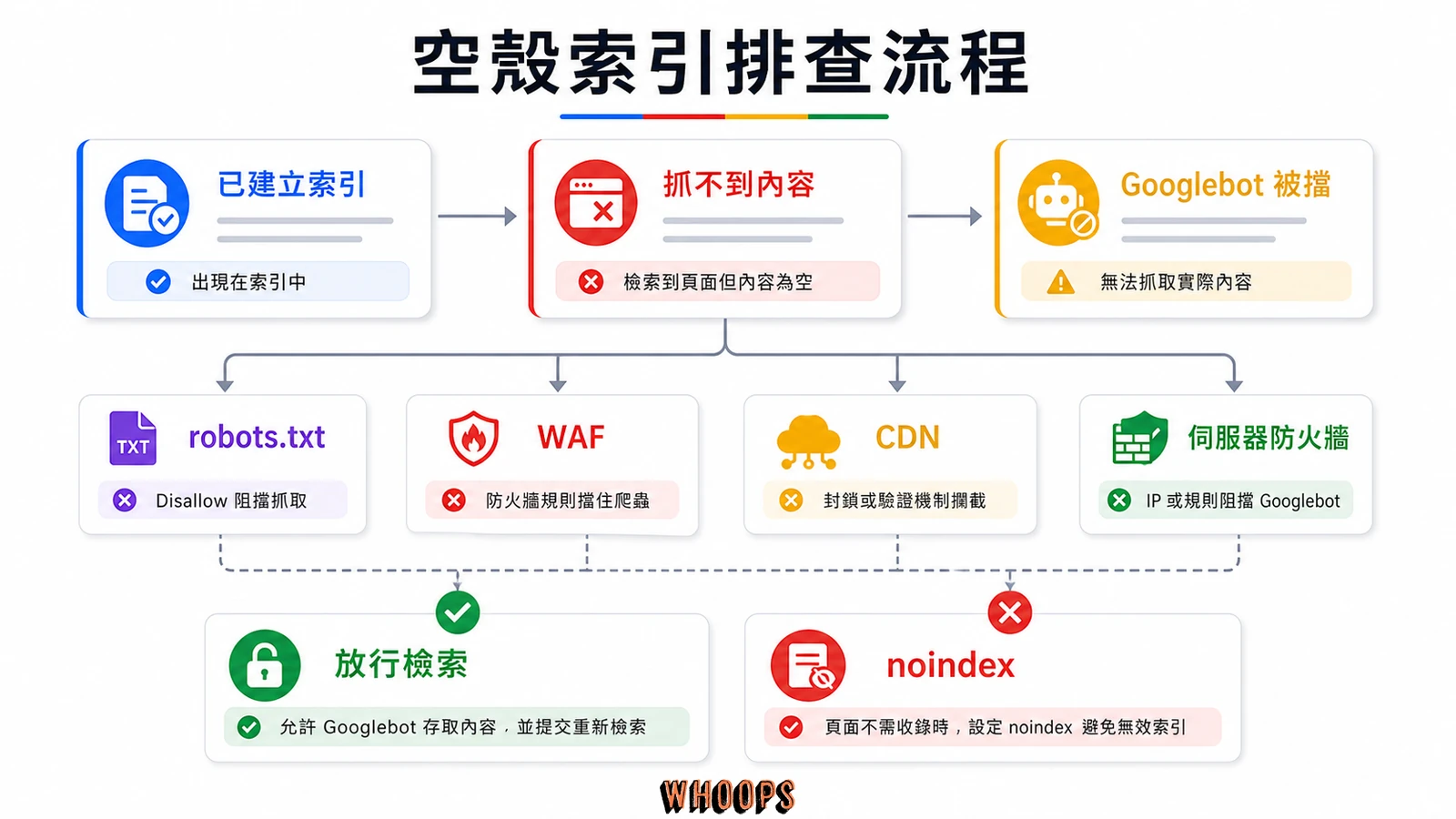
三種成因分類:先搞清楚你屬於哪一種
把成因拆成三大類,修復方向才不會搞混。第一類是 robots.txt 明確 Disallow,看檔案就知道;第二類是伺服器、CDN、WAF 封鎖 Googlebot IP,這是最常見也最隱蔽的;第三類是頁面本身真的沒內容或被判定 soft 404,屬於內容問題。先分類,才不會白忙,底下這張表把三類一次對齊。
| 成因類型 | 如何辨識 | 修復方向 |
|---|---|---|
| robots.txt 封鎖 | 打開 /robots.txt 看到 Disallow 涵蓋該路徑 | 移除或縮小 Disallow 範圍 |
| 伺服器/CDN/WAF 封鎖 | GSC 測試公開網址失敗,日誌出現 Googlebot 的 403 或 5xx | 放行 Verified Googlebot,調整 WAF 規則 |
| 內容空白或 soft 404 | 頁面回傳 200 但內容極薄,或根本是查無結果頁 | 補實內容,或改回 404/410 並移除索引 |
我看過太多站長把第三類當第二類修,改了一整個月的防火牆都沒用,因為根本是內容太薄被當 soft 404。判斷的方式不難:用 GSC 測試公開網址,看回傳的 HTML 內容長度,如果 HTML 是完整的,那問題就不在抓取,而在內容本身。這時候要往 內容品質 的方向去修,而不是去動伺服器,相關概念跟 關鍵字堆砌 一樣,過與不及都會被演算法扣分。
第一類 robots.txt:直接看檔案最快
第一類最好排查,打開你的網址加上 /robots.txt,逐行看 Disallow 規則有沒有涵蓋受影響路徑。常見的誤殺包括 Disallow: / 這種一竿子打翻整站的設定,或萬用字元規則繼承把不該擋的路徑也擋了。WordPress 生態裡,某些外掛預設會封鎖 /?s= 搜尋頁,但規則寫得太寬,連帶擋到其他正常頁面,這類情況在 WordPress SEO 最佳化 的設定檢查裡很常見,搭配 Site Kit by Google 可以更快發現哪些頁面掉了索引。
第三類內容問題:別用工具判斷,用眼睛看
第三類最容易誤判。很多工具看到 HTTP 200 就回報正常,但其實頁面回傳的是「查無結果」的空殼。這種 soft 404 對 Google 來說跟沒內容沒兩樣,會被歸進「已建立索引但未包含內容」。判斷方式是實際打開頁面看,如果整頁只有一句「找不到資料」或一張圖,那就是 soft 404。修法是補實內容,或老實回 404 並透過 移除索引 的方式處理掉。
排查第一步:用 GSC 網址檢查工具確認現況(唯一真理)
開啟 GSC,上方網址檢查欄貼上受影響網址,點「測試公開網址」。這裡的請求是從 Google 基礎設施發出,所以它是唯一能準確重現問題的環境。如果這裡顯示失敗或封鎖,那就是鐵證,不要再拿本地瀏覽器或 curl 的結果來反駁。
重點要看「查看測試頁面」裡的 HTTP 回應狀態碼與封鎖原因。正常應該是 200,如果你看到 403、429、5xx,那就是被伺服器端擋下,方向立刻指向防火牆或 CDN。要特別比對兩個狀態:「已建立索引的網址」是歷史快照,「測試公開網址」是即時結果。如果即時測試成功但舊狀態還是紅字,代表問題已經修了,只是在等 Google 重新抓取,這時候要的是耐心,不是再改東西。對 SERP 上頁面消失與否的判斷,可對照 什麼是 SERP 的基本結構。
這裡要提醒一件事:測試公開網址有頻率限制,不要狂點。每次測試都會消耗 Google 的資源配額,短時間內重複測同一個網址可能被暫時擋下。如果你的站點多,建議一次抓幾個代表性網址測就好,不需要把整個受影響清單都跑一遍。對 GSC 各種報告的角色不清楚的話,可以先看 Google SEO 入門資源 這類工具怎麼把資料對應回 GSC。
排查第二步:檢查 robots.txt 與 noindex 設定
打開你的網址加上 /robots.txt,逐行看 Disallow 規則有沒有涵蓋受影響路徑,再用 GSC 內建的 robots.txt 測試工具模擬 Googlebot 抓取,確認規則真的是你想的那樣。同時檢查頁面原始碼裡有沒有殘留的 <meta name=”robots” content=”noindex”>,以及伺服器回應標頭裡的 X-Robots-Tag。
WordPress 最常見的陷阱是 SEO 外掛的總開關。Yoast 或 Rank Math 都有一個「阻擋搜尋引擎索引整站」的開關,測試站忘記關就直接上線,整站瞬間變無內容。另一個常見陷阱是分類、標籤、作者封存頁被設成 noindex,結果連帶影響到從這些頁面連出去的內容頁被判定為低價值。想理解 noindex 跟 301 重定向 這類設定的連鎖影響,建議把網站的索引藍圖畫一遍。
noindex 與 Canonical 的搭配陷阱
這裡還有一個進階陷阱:noindex 跟 canonical 一起用時的優先級。如果你同時下了 noindex 和指向別頁的 canonical,Google 的行為會以 noindex 為優先,可能讓你的 canonical 失效。這在處理 重複內容 時特別容易踩到,因為很多人想用 noindex 解決重複頁,又同時掛 canonical 想集中權重,結果兩頭都沒達成。記住一個原則:要索引的頁面不要疊太多負面訊號,一個設定一個目的最清楚,跟 canonical 不保證生效 是同一類的教訓。
排查第三步:檢查 CDN 與防火牆(Cloudflare 使用者必看)
CDN 與 WAF 會不會擋 Googlebot?會,而且這是台灣最常見的成因。Cloudflare、Sucuri、AWS CloudFront 都可能,但 Cloudflare 因為市佔高,問題最集中。登入後台,逐一檢查 Bot Fight Mode、Super Bot Fight Mode、WAF 自訂規則、IP Access Rules、Rate Limiting 規則,看有沒有誤擋。
最佳做法是改用「已驗證的 Googlebot」(Verified Bot)放行機制,而不是手動加 IP 白名單。Cloudflare 維護一份已驗證爬蟲清單,Googlebot 在內,放行這份清單最安全,因為它會自動過濾掉偽造 Googlebot UA 的惡意流量。為什麼不要手動加 IP 白名單?因為 Google 的 IP 範圍會變動,你可以參考 Google 官方公佈的 IP 範圍(goog.json)做交叉驗證,但手動維護白名單很容易漏掉新段,過幾個月就失效。
Bot Fight Mode 與 Super Bot Fight Mode 的差別
Bot Fight Mode 是免費方案就有的功能,開啟後會對「疑似自動化」的流量發出挑戰,對 Googlebot 這種合法爬蟲可能誤殺。Super Bot Fight Mode 是付費功能,分級更細,可以對已驗證爬蟲、自動化但無害、惡意爬蟲分別設策略。我會建議對已知良好爬蟲明確放行,只對惡意來源挑戰,而不是無差別開啟 Bot Fight Mode。這跟 網站架構最佳化 一樣,設定要精準,不能圖方便全開。
還有一個容易被忽略的地方:CDN 業者會自動推播新的預設規則,沒改設定不代表沒事。你可能三個月前檢查過都正常,結果上週 Cloudflare 推了一條新規則,預設啟用,就把你的 Googlebot 擋下了。所以要定期檢查 WAF 的事件紀錄,看有沒有 Googlebot 被挑戰或封鎖的紀錄。台灣其他常見組合如 Sucuri、AWS CloudFront、各家 CDN 廠商內建的 WAF,排查邏輯都一樣:找 bot 防護設定、找 IP 封鎖規則、看事件紀錄。這層觀念跟 網站速度 的 CDN 設定是同一套基礎設施思維。
排查第四步:伺服器日誌分析,找出 Googlebot 的真實回應碼
沒有 CDN 或 CDN 檢查沒問題,還能去哪裡找證據?去伺服器 Access Log。搜尋含 Googlebot 字樣的請求列,看成對的 HTTP 狀態碼。正常是 200,如果看到大量 403、5xx、或 429,就確認是被伺服器端擋下。這是最底層、也最不會騙人的證據,因為它記錄的是伺服器實際回應給 Googlebot 的結果。
狀態碼各自代表什麼要分清楚。403 Forbidden 通常是權限或防火牆問題;429 Too Many Requests 是限流,代表你的伺服器或某層防護把 Googlebot 當成刷流量;5xx 是伺服器錯誤,可能是資源不足或程式崩潰。這幾種處理方式完全不同,403 往防火牆找,429 往限流設定找,5xx 往伺服器負載找。跟 Google Safe Browsing 封鎖機制 不同,這裡的封鎖是你網站自己造成的,不是 Google 主動懲罰。
User-Agent 可以偽造,要用反向 DNS 驗證
這裡有個關鍵:User-Agent 可以偽造,log 裡寫 Googlebot 不代表真的是 Google。驗證方式是對請求來源 IP 做反向 DNS 查詢,真正的 Googlebot 會解析成 *.googlebot.com 或 *.google.com 結尾的網域。如果你看到一堆假造 Googlebot UA 的請求回傳 403,那其實是好事,代表你的防護有擋到惡意流量;但如果你看到真正的 Google IP 回傳 403,那才是要修的問題。這層驗證在 技術 SEO 的價值 裡常被低估,但它是判斷「擋對了還是擋錯了」的唯一方法。
要誠實承認一個限制:很多中小站長根本拿不到伺服器日誌。用虛擬主機如 cPanel、Cloudways 的,要到後台找 raw log 下載;用共用主機的,可能得問客服才拿得到。如果真的拿不到 log,那就只能靠兩條線:CDN 的事件紀錄,加上 GSC 的測試公開網址。這兩條線交叉比對,雖然不如直接看 log 精準,但對多數中小網站已經夠用。如果連 CDN 都沒有,那就把重點放在 GSC 測試,它本身就是從 Google 基礎設施發出的真實請求。
修復後該做什麼:重新提交、請求索引、設定監控
修完不是放著等。要做三件事:第一,在 GSC 針對受影響網址點「請求建立索引」或「驗證修正」;第二,重新提交 XML sitemap 加速重新抓取;第三,設定長期監控,每週看網頁索引建立報告,避免下次又無聲掉索引。
「請求建立索引」與「驗證修正」的使用時機
這兩個按鈕用途不同。「請求建立索引」是你主動要 Google 來抓這個網址,適合剛修好、想加速收錄的情況,但有頻率限制,一天能請求的數量有限。「驗證修正」是你修好問題後,告訴 GSC「我改好了,請重新檢查」,它會排進 Google 的重新驗證佇列。一般來說,單頁修復用請求建立索引,大批頁面修復用驗證修正加重新提交 sitemap,效率比較好。對 sitemap 的角色不熟的話,可以先把 加速索引的實戰做法 看一遍,並參考 Google SEO 入門指南 的提交規範。
監控節奏建議每週一次,固定時間看網頁索引建立報告的狀態變化,同時留意曝光量、點擊量、排名有沒有異常下跌。如果你網站流量夠大,可以設定警示,例如某個分類的曝光量一天內掉超過一定比例就通知你。長期來說,建立一個 SOP:任何動到防火牆、CDN、伺服器設定之後,立刻跑一次 GSC 測試公開網址,這個習慣能避免八成的無聲故障。這個 SOP 跟 改善 SEO 的日常維護清單是同一個層級的基礎動作。
修完之後多久排名會回來?時間線與預期管理
沒有人能保證具體天數。實務上觀察 7 到 28 天是合理區間:修完後 Google 需要重新抓取、重新處理、再更新索引與排名,這幾個步驟都要時間。如果超過四週排名還沒回來,要回頭確認問題是不是真的修乾淨,而不是急著再做別的最佳化。影響復原速度的變數很多,網站抓取頻率、頁面數量、問題範圍是單頁還是大批量,都會影響時程。
觀察指標以 GSC 網頁索引建立報告的狀態變化為主,搭配曝光量、點擊量、排名。狀態從「已建立索引但未包含內容」變回「已建立索引」是第一個好消息,代表 Google 重新抓到了內容;接著曝光量會先動,排名與點擊會滯後一些。要耐心承認一件事:不要在這段期間反覆改東改西,過度調整反而干擾判斷,讓你分不清是哪個動作有效,這跟 SEO 就像健身需要時間 的節奏感是同一回事。
什麼時候該放棄單頁修復
如果同一個頁面修了兩、三輪,狀態還是不動,要考慮是不是該放棄單頁修復,改用 301 把權重導到一個新的、結構更乾淨的頁面。特別是那種內容已經過時、URL 結構又不理想的頁面,硬修不如重做。回到搜尋意圖,讀者要的是「我修對了沒」的確認訊號,而不是排名保證,這點跟 排名復原 的邏輯一致:先確認方向對,再談結果。
常見錯誤與排查陷阱:這些坑我看得太多
三個最常見的坑。第一,把 JavaScript 當萬用替罪羊,浪費幾天檢查前端,跳過基礎設施檢查。第二,用手動加 Google IP 白名單取代 Verified Bot 放行,結果 IP 變動後又失效,問題過幾個月重演。第三,以為 robots.txt Disallow 等於禁止索引,反而把想收錄的頁面搞成無內容。
第四個坑是改完沒重新提交 sitemap,被動等 Google 重新抓取,等太久。Google 的抓取排程不是即時的,大站可能要等幾週才輪到你的頁面,主動提交能省下這段等待。第五個坑是共用主機拿不到 log 卻硬要查,耗了一週什麼都沒找到,不如靠 CDN 事件紀錄與 GSC 兩條線。這幾個坑的本質都一樣:把力氣花在錯的層級,跟 黑帽 SEO 的風險一樣,方向錯了做越多越糟,跟 灰帽 SEO 踩線的教訓相通。
一個我實際看過的案例
講一個我實際處理過的案例。某站長發現整站 GSC 報紅字,花了一整個月調 Cloudflare 規則,關了又開 Bot Fight Mode,加了一堆 IP 白名單,問題完全沒改善。到頭來發現,是 WordPress 佈景主題裡有一個「網站維護模式」的開關被不小心啟用,回傳一個空的維護頁給所有訪客,包括 Googlebot。Cloudflare 從頭到尾都是無辜的。這個案例的教訓是:排查要從最接近內容的層級開始往下推,先確認頁面本身回傳的是不是正常內容,再去查 CDN、再查伺服器,順序反了就會在錯的地方打轉。
2026 AI 搜尋時代的調整:被擋的不只 Google
2026 年的搜尋結果頁不只有傳統十條連結,還有 AI Overview、ChatGPT 引用、Perplexity 摘要。當你的頁面被標記無內容,不只 Google SERP 排名掉,這些 AI 系統也抓不到你的內容來引用,等於同時失去傳統流量與 AI 引用兩條路。修復的優先級因此更高,因為損失是雙重的。
AI Overview 與傳統索引其實共用同一套抓取基礎。Googlebot 進不來,AI 摘要也沒料可抽,這在 AI Overviews 的運作機制裡講得很清楚。ChatGPT、Perplexity、Gemini 各自有爬蟲,像 GPTBot、PerplexityBot、Bytespider,但它們多半同樣會被過度激進的 WAF 擋下。研究指出,跨平台 AI 引用的重疊率偏低,大約只有一成多,代表你要同時放行多個 AI 爬蟲才能全面覆蓋,只放行 Googlebot 不夠,這也呼應 AI 搜尋流量重分配 的新現實。
不只查 Googlebot,也查 AI 爬蟲
驗證建議跟著升級:不只查 Googlebot,也查 GPTBot、PerplexityBot、Bytespider 這些 AI 爬蟲有沒有被擋。做法跟查 Googlebot 一樣,在 CDN 事件紀錄或伺服器 log 裡搜尋這些 UA,看成對的回應碼。要特別聲明一個限制:AI 爬蟲名單與各平台的封鎖規則變動很快,今天有效的清單下個月可能就過時,以各平台官方文件為準,不要背死清單。這層考量跟 AI SEO 與 AEO 的整體策略是綁在一起的,爬蟲放行是這套策略的地基,GEO 的佈局也建立在這個前提上。
實戰檢查清單:照著做,八成能自己修好
把前面所有步驟濃縮成一張按順序打的清單,從 GSC 測試公開網址出發,依序檢查 robots.txt、noindex、CDN/WAF、伺服器日誌,修完再重新提交 sitemap 並監控。打勾再往下走,不要跳步,這個順序是經過實戰驗證的,跳著做很容易漏掉中間環節。
- ☐ GSC 測試公開網址:正常應回 200,異常會出現 403/429/5xx(任何站長都能做)
- ☐ 看 /robots.txt:確認 Disallow 沒誤擋受影響路徑(任何站長都能做)
- ☐ 看頁面原始碼與 HTTP 標頭:確認沒有殘留 noindex 或 X-Robots-Tag(任何站長都能做)
- ☐ Cloudflare Bot 設定:檢查 Bot Fight Mode、Super Bot Fight Mode(需 CDN 管理權限)
- ☐ WAF 事件紀錄:搜尋 Googlebot 是否被挑戰或封鎖(需 CDN 管理權限)
- ☐ 伺服器 Access Log:搜尋 Googlebot 請求,看成對回應碼(需伺服器管理權限)
- ☐ 反向 DNS 驗證:確認 log 裡的 Googlebot 是真的(需伺服器管理權限)
- ☐ GSC 請求建立索引或驗證修正(任何站長都能做)
- ☐ 重新提交 sitemap.xml(任何站長都能做)
- ☐ 每週檢查網頁索引建立報告,設定流量警示(任何站長都能做)
每項都標了預期看到的正常狀態與異常狀態,也標了權限需求。如果你是委外的,把需要管理員權限的那幾項交給主機商或 CDN 廠商協助,自己能做的就先做。行動建議很明確:先做第一步,也就是 GSC 測試公開網址,拿到第一手證據,再決定往哪個方向修,這比任何猜測都可靠。這份清單可以跟 SEO 新手入門 的基礎清單搭配使用,一份管日常、一份管急診,Google 免費 SEO 工具 也能幫你省下不少檢測時間。
FAQ:讀者最常問的八個問題
已建立索引但未包含內容是什麼意思?
意思是 Google 已經把這個網址收進索引庫,但抓取時拿不到實際內容,頁面在搜尋結果裡形同空殼。成因通常是 robots.txt 封鎖、伺服器或 CDN 擋下 Googlebot,或頁面本身內容為空。
為什麼 Googlebot 被封鎖還是會建立索引?
因為 robots.txt 的 Disallow 只禁止抓取,不禁止索引。只要 Google 從站內連結、外部連結或 sitemap 得知網址存在,還是會放進索引,只是內容是空的。要真的禁止索引得用 noindex。
已建立索引但未包含內容要怎麼修復?
三步走:先用 GSC 網址檢查的測試公開網址確認現況,再查 robots.txt 與 CDN/WAF 設定,接著看伺服器日誌找 Googlebot 的真實回應碼。修完重新提交 sitemap,觀察 7 到 28 天。
Cloudflare 會擋 Googlebot 嗎?
會,這是台灣最常見的成因。Bot Fight Mode、Super Bot Fight Mode、WAF 自訂規則都可能誤擋。建議用 Verified Bot 機制放行已驗證的 Googlebot,不要手動加 IP 白名單,因為 Google IP 範圍會變動。
怎麼確認 Googlebot 真的被我的網站擋下?
用 GSC 的測試公開網址,它是唯一從 Google 基礎設施發出請求的工具。同時看伺服器日誌裡 Googlebot 對應的回應碼,如果是 403 或 5xx,就確認是被擋。記得用反向 DNS 驗證真的是 Google。
修完之後多久排名會回來?
實務上觀察 7 到 28 天是合理區間,這不是 Google 的官方保證。修完後 Google 要重新抓取、處理、更新索引與排名,受網站抓取頻率與問題範圍影響。超過四週沒回來,要回頭確認問題是否真修乾淨。
robots.txt Disallow 跟 noindex 有什麼差別?
Disallow 禁止抓取,但 URL 仍可能被索引;noindex 禁止索引,前提是 Google 要抓得到這頁才看得到指令。要索引就放行抓取,不要索引就用 noindex,且不能同時用 robots.txt 封鎖,否則 Google 看不到 noindex。
伺服器日誌裡 Googlebot 回傳 403 怎麼辦?
先確認那是不是真的 Google(反向 DNS 驗證 *.googlebot.com)。確認後往防火牆、WAF、CDN 規則找,看哪一層把 Google IP 擋下。修完重跑 GSC 測試公開網址驗證,再重新提交 sitemap。
回到搜尋意圖:先把通行證搞定,再談內容
回到一開始的結論:這個錯誤大多不是內容或 JavaScript 的問題,而是一場通行證糾紛。先把 Googlebot 的通行證搞定,也就是 robots.txt 放行加上 CDN 與防火牆不擋,再回頭談內容最佳化。順序錯了,做再多內容也進不了索引,因為 Google 根本看不到。三步行動清單複習一次:GSC 測試公開網址、查 robots.txt 與 CDN、查伺服器日誌。
要誠實聲明:修對方向能讓頁面重新進索引,但排名還取決於內容品質與競爭強度,沒有人能保證排名。你能控制的是把通行證發對、把證據找出來、把修復做完,剩下的交給時間。長期的 SOP 是:任何基礎設施變更後,跑一次 GSC 測試公開網址當驗收,這個動作能把八成的無聲故障擋在發生之前。想再深入,可以延伸閱讀 各種 SEO 最佳化技術 的完整指南,或對照 用 Google Trends 挖關鍵字 把修復後的頁面重新佈局,讓流量不只是回來,還能進一步成長。