
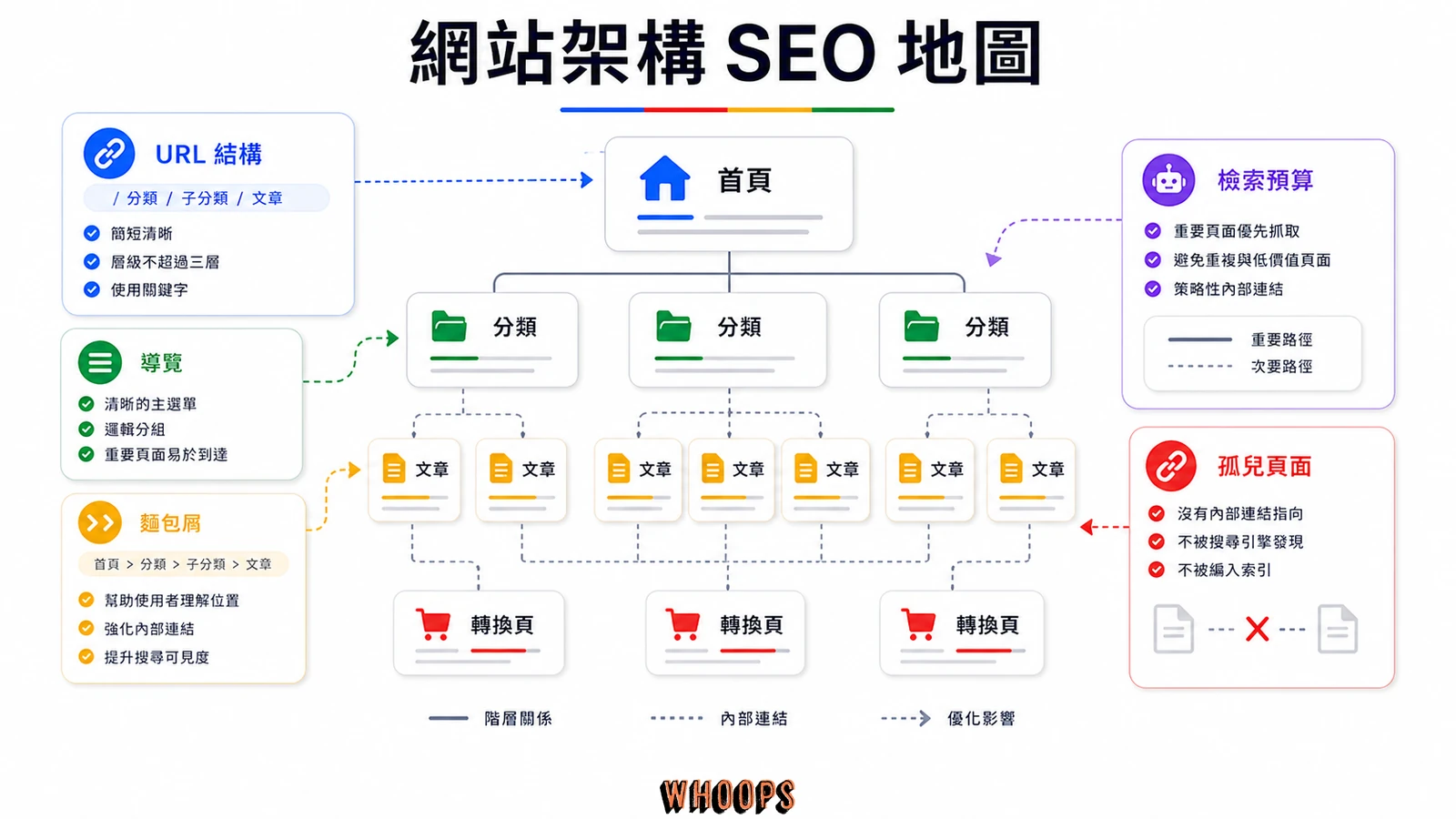
網站架構最佳化,指的是把你網站頁面之間的層級與連結關係整理成淺而清楚的樹狀結構,讓使用者與搜尋引擎都能在幾次點擊內找到重要內容。它不會直接給你一個排名分數,但它決定了 Google 能不能找到你的頁面、能不能看懂主題歸屬、能不能把首頁的權重傳到深層文章。Google 在 Search Central 文件裡反覆強調,結構清楚的網站更容易被完整檢索與建立索引;實務觀察也顯示,頁面距離首頁越遠,被收錄與排名的機會越低(差距依站而異,並非固定比例)。說白了,結構爛,單篇文章寫再好也排不上;結構順,新內容會被自然推上去。
TL;DR:網站架構影響的不是排名公式裡的某個係數,而是「可發現性」與「權重流動」。先把重要頁面壓在三到四次點擊內、URL 短而一致、麵包屑加 BreadcrumbList、檢索預算別浪費在參數頁,孤兒頁面接回主題叢集,結構就會從樹枝升級成網。
文章目錄
網站架構最佳化到底是什麼?為什麼它決定你能不能排上去
先把結論講清楚:架構影響的是可發現性和權重流動,不是排名公式裡的某個係數。Google 從來沒說「網站結構 = 多少分」,但它的檢索、索引、排名三階段每一步都受結構影響。結構亂,爬蟲進得來卻走不到深層頁面,分類關係也看不清楚,再多好內容都被埋在第二層以下。
用白話說,網站就像一棟房子。客人走進樣品屋,動線清楚,從玄關、客廳、書房一路能猜到下一間是什麼;迷宮式倉庫則讓人三分鐘就想離開。Googlebot 也是客人,差別只在它靠連結走,而不是靠門。連結斷了、分類錯了、深層頁面沒人指,它就只能摸到一小圈,自然收不到你精心寫的長文。
我用一個自己接過的案子開場。客戶網站有三百多篇文章,但 Search Console 顯示只有六篇穩定被建立索引。問題不在內容差,而是分類頁全部設成 noindex,加上文章之間幾乎沒有內部連結,等於把整個網站拆成三百個互不相通的孤島。我們花了三週重建分類與叢集,被收錄的頁面數量才開始回溫。這就是架構的力量,也是這篇要拆解的主題。
要理解架構為什麼重要,得同時招待三位訪客。第一位是真實使用者,他要的是兩秒內猜到該點哪、買單流程不被打斷。第二位是 Googlebot,它靠連結走訪、靠分類與錨文字判斷主題。第三位在 2026 年已經不是邊角議題:AI 搜尋引擎的爬蟲,像是 ChatGPT、Perplexity、Google AI Overviews 背後那一批,它們同樣靠連結與結構化資料讀懂你的站,而且更看重「主題集中度」。三位訪客的需求不同,但答案高度重疊:結構越清楚,三者都受惠。
這篇只講結構層,不碰標題、meta、H 標籤的單頁調整。那些屬於站內 SEO的範圍,我們另有一篇總覽可以對照著看。如果你想知道的是「整體 SEO 該從哪開始」,SEO 是什麼那篇有更上位的入門地圖。
理想的網站結構長什麼樣?扁平化、金字塔與三點擊原則的取捨
沒有唯一正確答案,但「點擊深度越淺、越容易被發現」是鐵律。所謂三次點擊原則不是硬規定,而是一個提醒:任何頁面如果要在首頁點五、六下才到,它會被 Google 當成相對不重要,被檢索的優先順序也跟著下降。
點擊深度(click depth)講的是「從首頁連到這頁需要點幾次連結」。離首頁越遠,內部連結傳遞的權重越弱,這是 PageRank 流動的基本物理。你的首頁通常是全站權重最高的頁,每多一層,能分到的權重大約再打一次折扣。所以重要的賺錢頁、主力文章,不該被埋在分類→子分類→子子分類→列表→詳情的第五層底下。
金字塔、樹狀與完全扁平,哪種才適合你
金字塔或樹狀結構是主流:首頁在下,幾個主分類在第二層,內容頁在第三層,少數站會再往下開子分類。它的優點是層級清楚、主導覽不會爆炸,缺點是要刻意把重要頁面往上拉。完全扁平(所有頁面都從首頁一兩步到)只適合頁面很少的小站,一旦頁面破百,主導覽會塞不下,使用者反而更難找東西。
用白話講一句:你的網站不是越扁越好,而是「重要的頁面要離首頁近」。電商或大型內容站必須分層,否則導覽會失控;中小站可以更扁平,把十篇主力文章直接放進主導覽下的子分類,讓它們都落在三層以內。
層級過深的訊號,比你想的更嚴重
我自己會做一個快速檢查:在首頁隨便挑一條路徑,看能不能在三次點擊內到達網站最有價值的那篇文章。到不了,就是問題。深層頁面除了權重弱,還常常連麵包屑、內部連結都沒做好,等於雙重隱形。把它接回內部連結網路、或從分類頁直接連過去,是最快的修法。
如果你想更深入了解結構與外部資源如何搭配,可以對照我們另一篇網站結構與外部連結最佳化技巧,那篇把「結構」和「外部連結」綁在一起談,跟這篇的純架構視角互補。
URL 結構怎麼設計才會自己說話?階層、關鍵字與參數的取捨
好的 URL 短、全小寫、用連字號分隔、包含主要關鍵字、且層級反映分類。要不要把分類放進 URL 沒有絕對答案,但一旦決定就別再改;至於參數 URL,能去掉就去掉,去不掉就靠 canonical 與 robots.txt 收斂。URL 是給人和機器看的短描述,不是堆關鍵字的看板。
好 URL 與壞 URL 的對照
| 壞的 URL | 好的 URL | 問題出在哪 |
|---|---|---|
| /prd/p_id=123 | /seo-service/website-architecture | 無意義參數,看不出主題 |
| /blog/post-20240315 | /blog/website-architecture | 只有日期沒主題,難以記憶 |
| /category/seo/子分類/文章全標題超長 | /seo/website-architecture | 層級過深、中文過長 |
| /Tag/SEO_Tools | /seo-tools | 大小寫混用、底線不利閱讀 |
關鍵字放進 URL 有幫助,但別堆砌。研究與實務經驗都顯示,URL 是 Google 理解頁面主題的次要訊號之一,把主要關鍵字放進去,比放一串代碼更有利。不過 Google 也講過,URL 的權重不高,過度塞關鍵字反而會被當成操控。一個乾淨的做法:URL 寫主關鍵字,標題寫完整長尾。
分類要不要寫進 URL:兩派各有理
把分類寫進 URL(例如 /seo/website-architecture/)的好處是層級一目了然,使用者與機器都能從網址猜到分類;壞處是一旦文章換分類,URL 就得改,處理不好就掉排名。不把分類寫進 URL(例如 /website-architecture/)的好處是 URL 穩定、不怕搬分類;壞處是層級訊號弱一點。重點不是哪派對,而是「一致」和「改了要做 301」。關於 301 的完整做法,可以看301 與 302 重定向完整指南。
參數 URL 是檢索預算殺手
?id=、?sort=、?page=、?utm_source= 這類參數會讓同一份內容產生無數個版本,吃掉你的檢索預算,也製造重複內容。收斂方法有三:用 canonical 指向標準版、用 robots.txt 封掉無價值的參數路徑、或在 Search Console 的網址參數工具裡指定每個參數的處理方式。三種可同時用,但別互相打架。
大小寫、結尾斜線、HTTP 或 HTTPS 也要統一。對 Google 來說,/SEO 和 /seo 是兩個 URL,/page 和 /page/ 也是。把它們統一規則、用 301 或 canonical 收斂,才不會把權重切成好幾份。HTTPS 更不用說,現在是基本配備,沒上 HTTPS 的站幾乎等於自廢武功。要了解中英文網址的差異,可參考非英文網址的真實影響。
這裡要誠實承認一件事:URL 改版是大工程,不是看到文章就衝動去改。改一次 URL 意味著要逐一做 301、更新所有內部連結、重新提交 sitemap、等 Google 重新檢索。先想清楚值不值得,再動手。如果你只是想從代碼型 URL 換成語意型 URL,效益通常值得;如果是為了「看起來更整齊」而改,那把那個力氣省下來。
導覽列與分類法怎麼規劃?讓人跟機器都不會迷路
主導覽列放五到七個最重要、用搜尋者聽得懂的詞命名的分類;分類依主題而非公司內部結構來分;每個分類底下再開必要的子分類。判斷標準只有一個:使用者能不能在兩秒內猜到該點哪。猜得到就對,猜不到就改。
主導覽列的設計原則
導覽列要用純文字連結,不要用圖片或 JavaScript 按鈕包到 Googlebot 走不到。命名用直觀詞,例如「關於我們」「服務項目」「聯絡我們」「部落格」,而不是自創品牌詞或縮寫。項目五到七個是甜蜜點,超過七個會讓使用者選擇癱瘓,少於三個又顯得單薄。必要時用下拉式選單整理子分類,但下拉層級別超過兩層,否則行動版很難點。
我看過把「最新消息」當主分類的網站,結果點擊率超低,因為使用者根本不知道裡面有什麼。與其放一個空泛的「最新消息」,不如直接放「SEO 教學」「AI 工具」「演算法更新」這種講得出內容的分類,點擊意圖會明確得多。
分類法:主題、產品線與標籤的選擇
分類法(taxonomy)常見有三種:主題分類(依內容主題)、產品線分類(依商品或服務)、標籤(tag)。主題分類適合內容站,產品線分類適合電商,標籤則是輔助索引。判斷用哪種,要看你的使用者怎麼找東西。台灣站最常見的亂象是「分類跟標籤重複」:分類叫 SEO,標籤也叫 SEO,結果產生兩份薄頁互相搶排名,這就是主題叢集做不起來的常見原因。
處理原則:分類用來切主題大架構,一篇文章只屬於一個分類;標籤用來做橫向關聯,一篇文章可掛多個標籤,但每個標籤都要有足夠的文章支撐,否則會變成只掛一篇文章的孤兒標籤頁。掛一篇文章的標籤頁幾乎沒有 SEO 價值,直接拿掉。要進一步了解怎麼把單篇文章調好,可以看什麼是 On-Page SEO,那篇專講標題、meta、內容層的最佳化。
頁尾與行動版導覽的輔助角色
頁尾連結(footer navigation)是主導覽的延伸,放聯絡資訊、隱私權政策、重要分類、熱門文章。它對 SEO 的直接幫助有限,但能讓重要頁面再多一條連結路徑,也方便使用者找資料。行動版導覽則要特別處理漢堡選單:Google 能讀懂漢堡選單裡的連結,但點擊可及性差的選單會讓真實使用者找不到,連帶影響停留與停留時間。
行動版還要留意一個觀念:手機版不是桌機版的縮水。在行動優先索引下,Google 主要看的是手機版內容與結構。如果手機版導覽少了一整塊分類,那等於告訴 Google「那些分類不重要」。想了解自適應設計與 SEO 的關係,可參考RWD 網頁設計與 SEO。
麵包屑導覽為什麼不能省?使用者的 GPS 也是 Google 的結構訊號
麵包屑同時服務使用者和搜尋引擎:給人一條回上一層的捷徑,給 Google 一條「這個頁面屬於哪個分類」的明確訊號。要做對,除了視覺呈現,還要加上 BreadcrumbList 結構化資料,否則 Google 只能猜。猜錯了,你的頁面會被歸到錯分類,主題權威也跟著歪。
三種麵包屑,只有一種是 SEO 要的
麵包屑分三種。路徑型(path)依使用者走過的足跡顯示,例如「首頁 → 上一頁 → 目前頁」,這對 SEO 沒用,因為它隨人而變。屬性型(attribute)依商品屬性顯示,例如「首頁 → 紅色 → 棉質 → T恤」,電商常用。位置型(location)依網站階層顯示,例如「首頁 > 分類 > 子分類 > 目前頁面」,這才是 SEO 要的,因為它穩定、可被結構化、能講清楚頁面歸屬。
BreadcrumbList 結構化資料:不做等於沒做
只有視覺麵包屑還不夠,要用 Schema 標記成 BreadcrumbList,Google 才會在搜尋結果顯示麵包屑路徑,而不是一串難看的完整網址。Rank Math、Yoast、The SEO Framework 這類外掛都能自動產生,只要分類設定正確,開啟選項即可。對結構化資料不熟的人,可以先看什麼是結構化資料打底。麵包屑這裡只講 BreadcrumbList,其他 schema(Article、FAQ、HowTo)屬於單頁層,可參考頁面 SEO 最佳化那篇對照。
麵包屑常見的三個錯誤
- 麵包屑連到 noindex 的頁面:等於告訴 Google「這分類不重要」,權重流不過去。
- 麵包屑跟主導覽分類不一致:主導覽說屬於 A 分類,麵包屑卻寫 B 分類,訊號打架。
- 手機版把麵包屑藏起來:行動優先索引下,藏起來等於不存在,結構化資料照樣要輸出。
你上次在 PTT 或網購站靠麵包屑走回去是什麼時候?那就是它的價值。對使用者來說,它是回上一層的捷徑;對 Google 來說,它是分類歸屬的GPS。兩個用途同一個元件,所以怎麼做都不虧。如果想看麵包屑跟 Sitelinks 的關聯,可以對照Sitelinks 怎麼自動出現。
檢索預算是什麼?中小網站到底要不要在意 crawl budget
檢索預算是 Google 願意在你網站上花多少時間抓頁面的上限,由檢索速率上限和檢索需求兩件事決定。事實是:頁面少的小站幾乎不用管它,但只要你的站達到一定規模,或塞滿了低價值的參數頁與重複內容,檢索預算就會變成收錄不全的元兇。Google 自己在 Search Central 文件裡講得很白:大多數網站不用擔心檢索預算。
拆解兩個組成:速率上限與檢索需求
檢索速率上限(crawl rate limit)跟伺服器承受度有關。如果你網站回應慢、常回 5xx,Google 會自動放慢檢索速度以免把你壓垮。檢索需求(crawl demand)跟頁面受歡迎程度與更新頻率有關,越多人連、越常更新,Google 越想抓。兩者相乘就是你每天被檢索的頻次上限。想看實際數字,到 Search Console 的「檢索統計資料」報表,裡面有每天抓多少頁、平均回應時間、各狀態碼分佈。
怎麼浪費檢索預算:七種常見吃法
- 重複內容:同一篇文章有多個 URL 版本,全部被抓。
- 分頁與排序參數:?page=2、?sort=price 產生大量變體。
- 軟 404:回傳 200 但內容是「找不到結果」的頁面,Google 要抓了才知道沒用。
- 被 noindex 但沒 disallow:noindex 還是會被抓,只是不建索引,照樣耗預算。
- 無限滾動陷阱:每往下滾就載入新 URL,產生無止盡的可檢索頁。
- 低品質分頁:薄內容、自動產生的標籤頁、空的彙整頁。
- _facet 篩選頁:電商的顏色、尺寸、價格組合,動輒產生上千個版本。
怎麼省檢索預算:五個動作
- robots.txt 封掉無價值路徑:把 /search/、/filter/、內部搜尋結果頁直接擋掉。
- canonical 收斂重複:每組重複 URL 指定一個標準版。
- 用網址參數工具:在 Search Console 指定 ?sort=、?page= 的處理方式。
- 定期清軟 404:把回 200 的「找不到頁」改成真正的 404 或 410。
- 合併薄內容頁:把三篇只寫兩百字的短文併成一篇長文,或直接刪。
別被嚇到去過度最佳化。我看過有人把整個 /tag/ 都封掉,結果把有流量的標籤頁也一起封死了,等於自斷一條流量來源。原則是:封掉的是「沒價值的版本」,不是「整個分類」。要進一步了解索引出問題的案例,可參考加速索引的實戰指南,以及 GSC 報表常見的已建立索引但未包含內容這類疑難排解。
孤兒頁面與深層頁面:你的網站裡藏著多少 Google 找不到的內容
孤兒頁面是存在於你網站、卻沒有任何內部連結指向它的頁面。它對使用者隱形,對 Google 也近乎隱形。找出方法是把你的網站爬蟲結果,跟 XML sitemap 和伺服器日誌交叉比對;救法只有兩條:要嘛加內部連結把它接回結構,要嘛確認沒價值就刪除或合併。
孤兒頁面是怎麼誕生的
- 舊活動頁下架沒處理:活動結束後頁面留在站上,但原本連到它的活動 banner 被移除。
- 分類被刪但文章還在:分類頁刪除後,原本掛在底下的文章失去連結來源。
- 分頁連結斷掉:列表頁改版後,第 5 頁之後的頁面再也連不到。
- A/B 測試或登入頁遺留:測試結束但變體頁面沒清掉。
為什麼孤兒有害:佔預算、稀釋主題、損害信任
孤兒頁面有三個害處。第一,它佔檢索預算,Google 抓了它卻拿不到足夠的連結訊號。第二,它稀釋主題集中度,一份內容被孤立在主題叢集之外,無法累積權威。第三,它可能是過時內容,例如三年前的舊活動頁還在線上,使用者點進去會覺得網站沒在維護,損害信任度,而信任正是E-E-A-T裡的 T。
怎麼找:三份清單交叉比對
找出孤兒頁面的標準做法是三份清單比對。第一份:用 Screaming Frog 或 Sitebulb 爬全站,得到「站內有連結能走到的頁面清單」。第二份:你的 XML sitemap,也就是「你告訴 Google 存在的頁面清單」。第三份:伺服器日誌(log file)裡被 Googlebot 實際抓過的頁面清單。三份清單的差集,就是那些「存在卻沒人連到、沒被抓、或被抓了卻沒在 sitemap」的頁面。如果你沒有伺服器日誌,至少做到前兩份比對,也能抓出大多數孤兒。Ahrefs 與 Sitebulb 也有視覺化的結構圖功能,能直接看出哪些頁面是懸空節點。
救法決策樹:接回、擴充、轉址還是刪
- 有價值:從相關的高流量頁加入連結,把它接回主題叢集。
- 薄內容:擴充成完整文章,或合併到既有主題頁。
- 過時:更新內容,或 301 到較新的替代頁。
- 純垃圾:直接刪除,並讓它回真正的 404 或 410。
講個小故事。幫一個客戶做盤點時,發現他三年前寫的一篇長文被當成孤兒丟在分類外,主題正好是目前熱門的長尾關鍵字。我們從三篇相關文章加入連結指向它,兩個月後排名就慢慢回來,還帶進穩定流量。孤兒頁面不一定是壞頁,常常只是被遺忘的好頁。如果你對內部連結怎麼佈局還不熟,內部連結最佳化策略有完整框架。
Sitemap、內部連結與主題叢集:把結構從骨架升級成網
sitemap 是你交給 Google 的頁面清單,內部連結是 Google 實際走訪的路徑,主題叢集是你刻意把相關內容串在一起的策略。三者缺一:只有 sitemap 沒內部連結,頁面被抓但權重傳不到;只有內部連結沒叢集策略,結構會越長越散;三者齊備,網站才會像網而不是樹枝。
XML sitemap 與 HTML sitemap 各司其職
XML sitemap 給 Google 看,是機器讀的頁面清單,要在 Search Console 提交。HTML sitemap 給人看,是一個列出全站主要頁面的單頁,方便使用者瀏覽。兩者都要有,但 XML 是主力。提交流程是:產生 XML 檔放到網站根目錄或 /sitemap.xml,再到 Search Console 的 Sitemaps 報表填入網址,Google 會回報提交了多少、已建立索引多少。工具可用 XML Sitemaps 產生器快速產一份。
但 sitemap 不是萬能。它只是「告訴 Google 這些頁面存在」,不代表 Google 會認真抓或給排名。真正的權重傳遞靠內部連結。很多人以為裝了 SEO 外掛自動產生 sitemap 就沒事了,結果 sitemap 裡全是低品質頁,等於把垃圾清單交給 Google,反而拉低整體品質訊號。提交前先過濾掉薄內容與重複頁,sitemapping 的價值才會出來。
內部連結策略:錨文字、相關性與首頁導流
內部連結做對的關鍵有四。第一,錨點文字要有意義,不要全部用「點這裡」「閱讀更多」,錨文字是 Google 理解連結主題的重要訊號。第二,相關文章要真相關,亂連只會稀釋主題。第三,首頁與分類頁要連到重要內容,把高權重頁的流量導到目標頁。第四,定期審計,修掉斷連與孤兒。深入做法可參考外部連結與內部連結搭配的策略。
主題叢集:從樹枝變成網
主題叢集(pillar-cluster)是刻意把一個主題的相關頁面集中、互相連結、由一篇 pillar 頁統整的結構策略。pillar 頁是該主題的總覽,例如這篇就是「網站架構」的 pillar;子主題頁各自獨立成文,但都從 pillar 頁連出去,子主題之間也要互相連結。這樣做的好處是主題權威集中、權重內部循環、Google 與 AI 都更容易判斷你是該主題的權威。完整的叢集建立流程,可參考叢集內容與集群內容建立主題權威兩篇。
另一個相關概念是 hub page(樞紐頁)。某些分類頁或彙整頁可以刻意設計成 hub,把一個主題的權重集中,再對外連到子頁。hub page 跟 pillar page 的差別是:pillar 是內容總覽,hub 是連結樞紐。兩者常合而為一,但也可能是不同頁。
網站架構重構實戰步驟:從盤點、重規劃到安全改版不掉排名
重構要照順序:先盤點全部頁面與現有連結、再重新規劃分類與層級、接著處理 URL 變更與 301 轉址、到頭來上線後觀察收錄與排名變化。最大原則是:能不動 URL 就不動,動了就一定要 301、要送 sitemap、要監控。順序錯了,排名掉的機會比掉得多。
步驟一:盤點全部頁面與連結
匯出所有 URL,來源三個:XML sitemap、資料庫或 CMS 匯出、爬蟲結果。三份比對才能抓到隱藏頁。接著為每頁標註流量、排名、外部連結數、內部連結數,分出四類:留(有價值留著)、改(URL 或分類要改)、刪(沒價值刪掉)、併(薄內容合併)。這份分類表就是後續所有動作的依據,務必做成文件留存。
步驟二:重新規劃分類與層級
用心智圖工具畫新結構,XMind 或 Miro 都行。定義新的分類與層級,確認每個重要頁面都落在三次點擊內。這一步要反覆檢查:哪些頁面要被往上拉、哪些要合併、哪些要拆開。畫完後,把新結構對照舊結構,標出每個 URL 的新舊對應關係。
步驟三:URL 變更與 301 轉址
能不改 URL 就別改;改了就逐一做 301 永久轉址。避免鏈式轉址(A→B→C),那會讓權重在每一跳流失,也讓 Google 多花檢索資源。每個 301 都要從舊 URL 一對一指向新 URL,並更新所有指到舊 URL 的內部連結,改指向新 URL。301 做對,權重會慢慢轉移,通常不會掉排名,甚至會更好。完整做法看網站改版 SEO 自守與 301 指南,想了解兩者差異可再看301 vs 302 哪個對 SEO 更友善。
步驟四:sitemap 與提交
產生新 sitemap,只放你想被索引的頁面,移除要刪除與合併的舊頁。提交到 Search Console 的 Sitemaps 報表,並用網址檢查工具請求重新檢索重要頁面,加速 Google 發現變更。被刪除的頁面要從 sitemap 移除,並讓它回真正的 404,這樣 Google 才會從索引清掉。
步驟五:上線後觀察與監控
上線後盯三個指標:GSC 的網頁索引報表(看收錄數變化)、檢索統計資料(看 Google 有沒有開始抓新結構)、排名波動(用第三方工具追蹤主力關鍵字)。預期會有短期波動,通常七到二十八天才會穩定。這裡用區間描述,不寫死天數,因為每站情況不同。我會建議,非必要別在旺季或大活動前重構,出事沒有緩衝時間。對排名復原有疑問,可參考排名下降怎麼復原與如何拿到第一名排名。
2026 年的網站架構:AI 搜尋與生成式引擎怎麼改變結構該怎麼蓋
AI 搜尋引擎爬你網站的方式跟 Googlebot 類似,但更看重「主題集中度」與「可引用的清晰段落」。2026 年的做法是:結構上把同主題的頁面收攏成清楚的叢集、每個頁面有獨立可引用的 URL、用結構化資料讓機器讀懂層級,並確保 AI 爬蟲沒有被 robots.txt 擋掉。先設限不誇大:AI 搜尋還在演進,沒有人能保證怎麼蓋一定被引用,但「結構清楚」是被引用的前提。
主題權威:AI 引擎更容易判斷你是不是權威
主題權威(topical authority)指的是,把一個主題的相關頁面集中、互相連結、由 pillar 頁統整,讓搜尋引擎判斷你是該主題的權威來源。AI 引擎在抽取答案時,會優先引用主題覆蓋完整、結構清楚的網站。如果你的站零散寫了三十個不同主題,AI 很難把你歸類為哪個領域的權威;反之,把三十篇文章收攏成三個主題叢集,每個叢集都有 pillar 與子頁,被引用的機會會明顯提高。想了解整套 AISO 思維,可參考什麼是 AISO與AI 搜尋新戰場 AISO。
頁面可獨立引用:每個子主題都有自己的乾淨 URL
AI 引擎引用時,偏好能獨立擷取的段落與穩定的 URL。每個子主題有自己的乾淨 URL、清楚的標題層級、獨立可被擷取的段落,會讓 AI 更容易把它抽進答案。不要把十個子主題塞在同一個超長頁面裡,再用錨點跳轉;那樣 AI 抽取時容易抓到錯段落,也無法給每個子主題獨立連結。獨立 URL 也方便在查詢擴充時被匹配到。
結構化資料升級與 robots.txt 的 AI 爬蟲問題
結構化資料在 AI 時代要升級。BreadcrumbList 之外,Article、FAQPage、HowTo 對 AI 引擎理解內容結構有幫助,特別是 FAQPage 能讓 AI 直接抓成問答片段。robots.txt 則要確認 GPTBot、PerplexityBot、Google-Extended、ClaudeBot 等 AI 爬蟲沒有被誤擋。要不要擋是你的商業選擇,但要知道擋了就等於放棄被引用的機會。想了解 AI 引用與搜尋的整體策略,可參考AEO 答案引擎最佳化與GEO 生成式引擎最佳化,以及針對 Google 生態的AI Overviews與AI 搜尋 SEO 指南。
說真的,現在問 AI 一個問題,它回的答案背後引用哪些網站,往往跟 Google 排名不是同一批。結構清楚的小站反而有機會被 AI 選中,因為 AI 看重的是內容能否被乾淨擷取、主題是否集中,而不是網域權重這種傳統訊號。這對中小站長是好消息,前提是你把結構蓋對。AI 爬蟲也會消耗伺服器資源,大型站要留意頻率限制,必要時在 robots.txt 設定 Crawl-delay。對整體趨勢有興趣,可看2026 AI 搜尋與 SEO 流量重分配。
網站架構常見錯誤與自我健檢清單:避開這些地雷就贏一半
最常見的結構錯誤就那幾樣:分類跟標籤重複造成一堆薄頁、分頁與篩選參數吃掉檢索預算、重要頁面埋太深、麵包屑缺結構化資料、舊頁沒處理變孤兒。照一份十項健檢清單走一遍,能抓出八成問題。剩下兩成要靠日誌分析與第三方工具,但先做完這十項,效益已經很高。
十個最常踩的結構地雷
- 分類與標籤重複:兩份薄頁搶同一個關鍵字,權重對半切。
- 分頁與排序參數未收斂:吃掉檢索預算,製造重複內容。
- 首頁點擊深度過深:重要頁面埋在五層以下,權重傳不到。
- 麵包屑未做 schema:視覺有做但沒 BreadcrumbList,等於沒做。
- 孤兒頁面未處理:舊頁沒人連,佔預算又稀釋主題。
- sitemap 過期或含低品質頁:把垃圾清單交給 Google。
- 內部連結全用「點這裡」:錨文字沒主題訊號,Google 讀不懂。
- 重複內容無 canonical:權重被切成好幾份。
- 軟 404 未清理:回 200 的「找不到頁」持續吃預算。
- robots.txt 誤擋重要路徑:把有流量的分類或標籤一起封掉。
自我健檢十步清單
- 到 Search Console 的網頁索引報表,看有多少頁「已檢索但未建立索引」。
- 用 Screaming Frog 爬全站,看點擊深度分佈,找出超過四層的頁面。
- 比對 sitemap 與爬蟲結果,找出孤兒頁面。
- 檢查每頁是否有 BreadcrumbList 結構化資料。
- 檢查內部連結錨文字,列出全部用「點這裡」「閱讀更多」的連結。
- 在檢索統計資料看每天抓多少頁、回應時間、狀態碼分佈。
- 用 Sitebulb 或 Ahrefs 的結構圖,找出懸空節點與深層叢集。
- 檢查 robots.txt,確認沒誤擋重要路徑。
- 搜尋 site:你的網域,看 Google 實際收錄多少頁,跟實際頁數比對。
- 抽查十個重要頁面,確認麵包屑、內部連結、canonical 都正確。
如果你只能做一件事,就先去 GSC 的網頁索引報表,看有多少頁被歸類為「已檢索但未建立索引」。那通常就是結構問題的第一個訊號。頁面被抓了卻沒建索引,多半是因為權重不足、內容重複、或被判定為低價值,這些都跟結構脫不了關係。工具清單部分,Google Search Console 是必備,Screaming Frog 與 Sitebulb 是結構分析主力,Ahrefs 與 Semrush 補上外部連結與孤兒偵測。
回到搜尋意圖:你會找上「網站架構最佳化」,多半是因為新文章排名不上、舊文章流量停滯、或 Google 收錄很慢。這些症狀的根,常常不在單篇文章,而在結構。把結構修好,是地基工程,地基穩了,單篇文章的最佳化才會發揮效果。想進一步把每一頁調到位,回到頁面 SEO 與主題集群與內容最佳化;想把技術層補強,看技術 SEO與網站程式碼最佳化。
網站架構常見問題 FAQ:讀者最常卡住的八個疑問
網站架構會影響 SEO 排名嗎?
會,但不是直接給你排名分數,而是透過兩個中介變數影響:可發現性與權重流動。結構好,Google 找得到你所有重要頁面、看懂主題歸屬、把首頁權重順利傳到深層內容,這些都會反映在收錄率與排名穩定度上。結構爛,再好的內容也排不上。
理想的網站點擊深度是幾層?
重要頁面控制在三次點擊內、一般頁面不超過四次點擊,是比較穩的範圍。沒有官方硬性數字,但點擊深度越淺,被發現與排名的機會越高,這是 PageRank 流動的物理。如果你的主力頁面要點五次才到,值得花時間把它往上拉。
URL 結構要包含分類嗎?
沒有絕對答案,重點是一致。把分類放進 URL 能呈現層級訊號,但文章換分類就得改 URL;不放分類則 URL 更穩定,但層級訊號弱一點。兩派各有理,選了一致執行就好。要改 URL 一定要做 301,否則排名會掉。
什麼是檢索預算?小網站需要在意嗎?
檢索預算是 Google 願意花在你網站抓頁面的時間上限,由檢索速率上限與檢索需求決定。頁面少的小站幾乎不用管,Google 自己會抓完。但只要站達到一定規模,或塞滿參數頁、重複內容、軟 404,檢索預算就會變成收錄不全的主因。判斷標準是去 GSC 看檢索統計,如果 Google 抓的速度跟不上你新增的速度,就該開始管。
怎麼找出孤兒頁面?
用三份清單交叉比對。第一份是爬蟲結果(Screaming Frog 或 Sitebulb),代表「站內有連結能走到的頁面」。第二份是 XML sitemap,代表「你告訴 Google 存在的頁面」。第三份是伺服器日誌,代表「Googlebot 實際抓過的頁面」。出現在 sitemap 或日誌、卻不在爬蟲結果裡的頁面,多半就是孤兒。
麵包屑對 SEO 有什麼實質幫助?
麵包屑同時幫使用者和搜尋引擎。對使用者,它是回上一層的捷徑,降低跳出率。對 Google,它是頁面分類歸屬的明確訊號,加上 BreadcrumbList 結構化資料後,還能在搜尋結果顯示麵包屑路徑而非完整網址。強烈建議做,而且一定要加 schema。
網站重構會不會掉排名?
短期可能有波動,但 301 做對、sitemap 重送、持續監控,排名通常會回來甚至更好。風險最大的不是重構本身,而是重構過程中的疏漏:忘了做 301、內部連結沒更新、sitemap 沒重送。照標準步驟走,七到二十八天內會穩定。
AI 搜尋時代,網站架構還重要嗎?
更重要。AI 引擎跟 Googlebot 一樣靠連結與結構化資料讀懂你的站,而且更看重主題集中度與可引用的清晰段落。把同主題頁面收攏成叢集、每頁有獨立可引用 URL、結構化資料齊全、確認沒擋 AI 爬蟲,這些都會提高被 AI 引用的機會。FAQ 細節可參考QAPage 結構化資料教學對問答片段的說明。
回顧一下這篇的重點:網站架構影響的是可發現性與權重流動,先把重要頁面壓在三到四次點擊內,URL 短而一致,麵包屑加 BreadcrumbList,檢索預算別浪費在參數頁與重複內容,孤兒頁面接回主題叢集,再用 sitemap 與主題叢集把結構從樹枝升級成網。2026 年 AI 搜尋興起後,結構清楚更是被引用的前提,這對中小站反而是機會。如果你正卡在新文章排名不上、舊文章收錄不全的困境,先別急著改單篇文章,花一個下午跑一次上面的十項健檢,八成的結構問題會浮現。先修地基,再修單頁,順序對了,後面的努力才會累積。想找人幫你看結構問題,也歡迎到我們的Vibe Coding SEO 最佳化服務頁面聊聊,或從SEO 權威完整解析開始把整體觀念補齊。